Giao dịch
Loại giao dịch
Giao ngay
Giao dịch tiền điện tử một cách tự do
Alpha
Point
Nhận các token đầy hứa hẹn trong giao dịch trên chuỗi được tối ưu hóa
Trước giờ mở cửa
Giao dịch các token mới trước khi chúng được niêm yết chính thức
Giao dịch ký quỹ
Tăng lợi nhuận của bạn với đòn bẩy
Giao dịch khối & Chuyển đổi
0 Fees
Giao dịch bất kể khối lượng, không mất phí, không trượt giá
Token đòn bẩy
Sản phẩm ETF có thuộc tính đòn bẩy, giao dịch giao ngay, không cần vay, không cháy tải khoản
Futures
Futures
Hàng trăm hợp đồng được thanh toán bằng USDT hoặc BTC
Quyền chọn
HOT
Giao dịch với các quyền chọn kiểu Châu Âu
Tài khoản hợp nhất
Tối đa hóa hiệu quả sử dụng vốn của bạn
Giao dịch demo
Bắt đầu với Hợp đồng
Nắm vững kỹ năng giao dịch hợp đồng từ đầu
Sự kiện tương lai
Tham gia các sự kiện để giành được những phần thưởng hậu hĩnh
Giao dịch demo
Sử dụng tiền ảo để trải nghiệm giao dịch không rủi ro
Kiếm tiền
Khởi động
Đầu tư
Simple Earn
VIP
Kiếm lãi từ các token nhàn rỗi
Đầu tư tự động
Đầu tư tự động một cách thường xuyên.
Sản phẩm tiền kép
Mua thấp và bán cao để kiếm lợi nhuận từ biến động giá
Quỹ định lượng
VIP
Đội ngũ quản lý tài sản hàng đầu giúp bạn kiếm lợi nhuận mà không cần lo lắng
Vay Crypto
0 Fees
Thế chấp một loại tiền điện tử để vay một loại khác
Trung tâm cho vay
Trung tâm cho vay một cửa
Trung tâm tài sản VIP
New
Quản lý tài sản tùy chỉnh giúp tăng trưởng tài sản của bạn
Thế chấp
Thế chấp tiền điện tử để kiếm tiền từ các sản phẩm PoS
BTC Staking
HOT
Stake BTC và kiếm APR 10%
ETH Staking
HOT
Stake ETH và kiếm APR 6%
Đúc GUSD
New
Sử dụng USDT/USDC để đúc GUSD với lợi suất tương đương kho bạc
Thế chấp mềm
Kiếm phần thưởng với staking linh hoạt
Thêm


- Chủ đề thịnh hànhXem thêm
398 Phổ biến
15.9K Phổ biến
37.3K Phổ biến
36.7K Phổ biến
2.2K Phổ biến
- Ghim
Tiết lộ Transformer trong iPhone: Dựa trên kiến trúc GPT-2, bộ phân đoạn từ chứa biểu tượng cảm xúc, do cựu sinh viên MIT sản xuất
Nguồn gốc: Qubits
“Bí mật” Transformer của Apple đã được giới đam mê tiết lộ.
Trong làn sóng các mẫu máy lớn, dù bạn có bảo thủ như Apple thì cũng phải nhắc đến “Transformer” trong mỗi buổi họp báo.
Ví dụ, tại WWDC năm nay, Apple đã thông báo rằng các phiên bản iOS và macOS mới sẽ được tích hợp sẵn các mô hình ngôn ngữ Transformer để cung cấp các phương thức nhập liệu với khả năng dự đoán văn bản.
Một anh chàng tên Jack Cook đã lật ngược tình thế của macOS Sonoma beta và phát hiện ra rất nhiều thông tin mới:
Chúng ta hãy xem xét chi tiết hơn.
Dựa trên kiến trúc GPT-2
Trước tiên, hãy xem lại những chức năng mà mô hình ngôn ngữ dựa trên Transformer của Apple có thể triển khai trên iPhone, MacBook và các thiết bị khác.
Chủ yếu được phản ánh trong phương thức nhập liệu. Phương thức nhập liệu của riêng Apple, được hỗ trợ bởi mô hình ngôn ngữ, có thể đạt được chức năng dự đoán từ và sửa lỗi.
** **### △Nguồn: bài đăng trên blog của Jack Cook
**### △Nguồn: bài đăng trên blog của Jack Cook
Mô hình đôi khi dự đoán nhiều từ sắp xuất hiện, nhưng điều này chỉ giới hạn trong các tình huống mà ngữ nghĩa của câu rất rõ ràng, tương tự như chức năng tự động hoàn thành trong Gmail.
** **### △Nguồn: bài đăng trên blog của Jack Cook
**### △Nguồn: bài đăng trên blog của Jack Cook
Vậy chính xác mô hình này được cài đặt ở đâu? Sau khi tìm hiểu sâu, Anh Cook xác định:
Bởi vì:
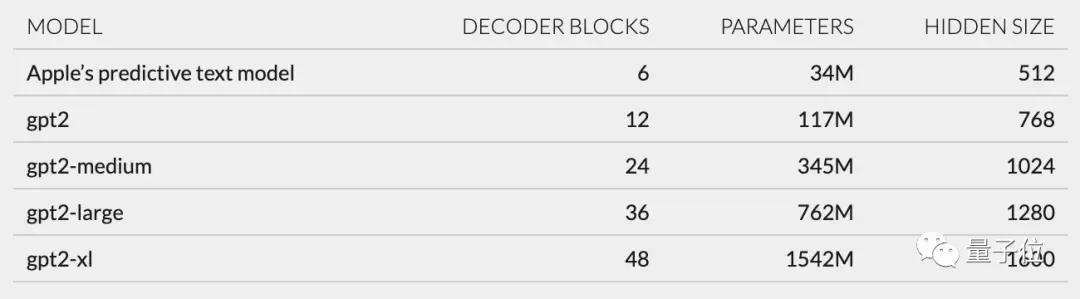
Hơn nữa, dựa trên cấu trúc mạng được mô tả trong unilm_joint_cpu, tôi đã suy đoán rằng mô hình Apple dựa trên kiến trúc GPT-2:
Nó chủ yếu bao gồm nhúng mã thông báo, mã hóa vị trí, khối giải mã và lớp đầu ra. Mỗi khối giải mã có các từ như gpt2_transformer_layer_3d.
** **### △Nguồn: bài đăng trên blog của Jack Cook
**### △Nguồn: bài đăng trên blog của Jack Cook
Dựa trên kích thước của mỗi lớp, tôi cũng suy đoán rằng mô hình Apple có khoảng 34 triệu tham số và kích thước lớp ẩn là 512. Tức là nó nhỏ hơn phiên bản nhỏ nhất của GPT-2.
Tôi tin rằng điều này chủ yếu là do Apple muốn một mẫu máy tiêu thụ ít điện năng hơn nhưng có thể chạy nhanh và thường xuyên.
Tuyên bố chính thức của Apple tại WWDC là "mỗi lần bấm phím, iPhone sẽ chạy mô hình một lần".
Tuy nhiên, điều này cũng có nghĩa là mô hình dự đoán văn bản này không giỏi lắm trong việc tiếp tục câu hoặc đoạn văn một cách trọn vẹn.
** **### △Nguồn: bài đăng trên blog của Jack Cook
**### △Nguồn: bài đăng trên blog của Jack Cook
Ngoài kiến trúc mô hình, Cook còn tìm hiểu thông tin về tokenizer.
Anh ấy đã tìm thấy một bộ gồm 15.000 mã thông báo trong unilm.bundle/sp.dat. Điều đáng chú ý là nó chứa 100 biểu tượng cảm xúc.
Cook tiết lộ Cook
Dù anh Cook này không phải là đầu bếp nhưng bài đăng trên blog của tôi vẫn thu hút rất nhiều sự chú ý ngay khi được đăng tải.
Trước đây, anh từng thực tập tại NVIDIA, tập trung nghiên cứu các mô hình ngôn ngữ như BERT. Ông cũng là kỹ sư nghiên cứu và phát triển cấp cao về xử lý ngôn ngữ tự nhiên tại The New York Times.
Vậy có phải sự tiết lộ của anh ấy cũng khơi dậy một số suy nghĩ trong bạn? Chào mừng bạn đến chia sẻ quan điểm của bạn trong khu vực bình luận ~
Liên kết gốc: