投資
ローンチパッド
CandyDrop
キャンディーを集めてエアドロップを獲得
Launchpool
クイックステーキング
潜在的な新しいトークンを獲得しよう
HODLer Airdrop
GTを保有して、大量のエアドロップを無料で入手
Launchpad
次の大きなトークンプロジェクトを一足先に
Alphaポイント
NEW
オンチェーン資産を取引して、Airdrop報酬を楽しもう!
先物ポイント
NEW
先物ポイントを獲得し、Airdrop報酬を受け取りましょう。
もっと
imJoker
現在、コンテンツはありません
imJoker
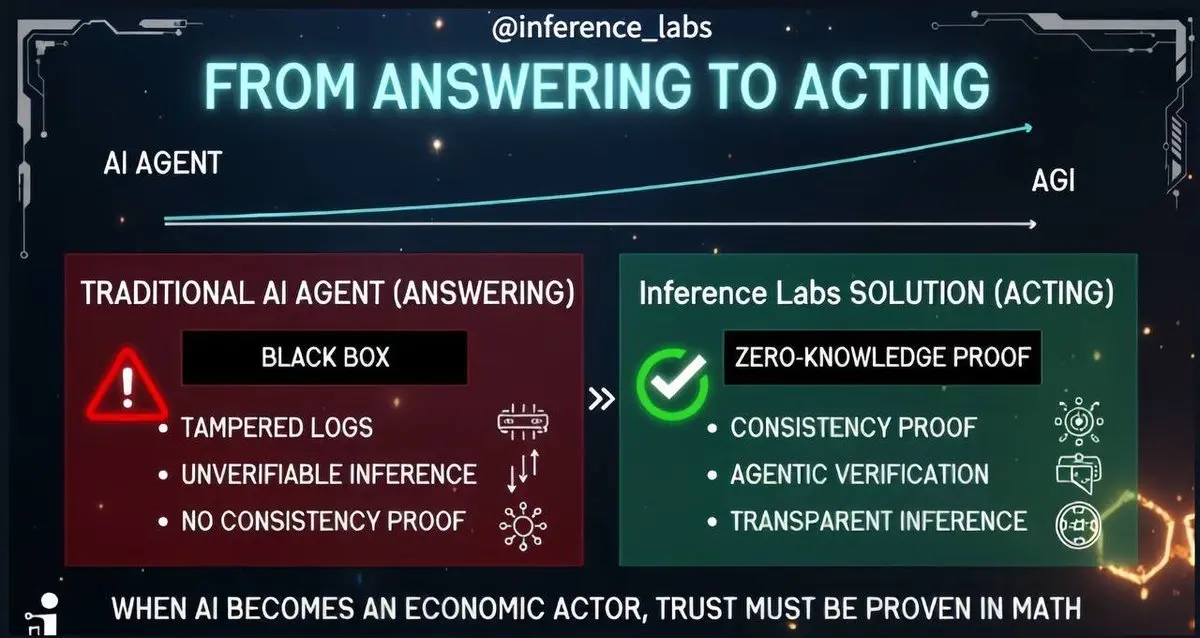
⚡️ 友友们、AI はすでに新しい時代に入りました。もはや単なる回答生成だけではなく、支払いの実行、オペレーティングシステムの運用、取引の実施、意思決定まで行います。
これは、AI が単なるツールではなく、行動能力を持つ主体になったことを意味します。しかし、その一方で核心的な問題が浮上します:このエージェント(Agent)の行動は正しいのか、信頼できるのか。
既存の AI アーキテクチャでは、この問いに答えることはできません。システムログは改ざんされる可能性があり、モデルの内部ロジックはブラックボックスのようなもので、その行動を根本的に検証することは困難です。
こうした背景の中で、Inference Labs の役割は非常に重要になっています。Inference は、ゼロ知識証明(ZK)に基づく検証層を構築し、AI 代理の行動を独立して検証可能にすることを目指しています。これにより、システム内部の不可視なプロセスに頼るだけではなく、透明性と信頼性を高めます。
一貫性証明(consistency proof)、エージェンティック検証(agentic verification)などの仕組みを通じて、Inference は次のようなことを検証可能な方法で示します:エージェントは方針に従っているのか?判断ロジックは一貫しているのか?実証に基づいて行動しているのか?これらはもはやモデルへの信
これは、AI が単なるツールではなく、行動能力を持つ主体になったことを意味します。しかし、その一方で核心的な問題が浮上します:このエージェント(Agent)の行動は正しいのか、信頼できるのか。
既存の AI アーキテクチャでは、この問いに答えることはできません。システムログは改ざんされる可能性があり、モデルの内部ロジックはブラックボックスのようなもので、その行動を根本的に検証することは困難です。
こうした背景の中で、Inference Labs の役割は非常に重要になっています。Inference は、ゼロ知識証明(ZK)に基づく検証層を構築し、AI 代理の行動を独立して検証可能にすることを目指しています。これにより、システム内部の不可視なプロセスに頼るだけではなく、透明性と信頼性を高めます。
一貫性証明(consistency proof)、エージェンティック検証(agentic verification)などの仕組みを通じて、Inference は次のようなことを検証可能な方法で示します:エージェントは方針に従っているのか?判断ロジックは一貫しているのか?実証に基づいて行動しているのか?これらはもはやモデルへの信
KAITO-3.17%
- 報酬
- いいね
- コメント
- リポスト
- 共有
⚡️ 友友们、分散型金融(DeFi)において、トレーダーや開発者はより効率的でスマートな操作方法を追求し続けています。
Theoriq AIが提供するAlphaSwarmは、革新的な技術です。これは単一の取引ロボットではなく、人工知能に駆動されたスマートエージェント群であり、まるで効率的な「金融脳」が自主的に意思決定し協力して実行します。
従来のDeFi取引戦略は複雑なスマートコントラクトやスクリプトを必要としましたが、AlphaSwarmは自然言語で戦略を入力できるようにします。例えば、「ETH価格が3%上昇したら買い」といった指示を出すと、スマートエージェント群が意図を理解し、市場をリアルタイムで監視し、EthereumやSolanaなど複数のチェーン上で操作を実行します。コーディングの知識がなくても、プロフェッショナルな取引体験を享受できます。
AlphaSwarmの核は、スマートエージェント群の協働にあります。システムは、タスクに応じてデータ分析、戦略生成、実行などさまざまな役割を持つエージェントを自動的に組み合わせ、投票や適応戦略によって意思決定を行います。この群集知能により効率が向上し、戦略の実行もより堅牢で柔軟になります。
市場は刻一刻と変化しますが、AlphaSwarmは強化学習を通じて戦略を絶えず最適化し、チェーン上の信用システムを使ってエージェントのパフォーマン
Theoriq AIが提供するAlphaSwarmは、革新的な技術です。これは単一の取引ロボットではなく、人工知能に駆動されたスマートエージェント群であり、まるで効率的な「金融脳」が自主的に意思決定し協力して実行します。
従来のDeFi取引戦略は複雑なスマートコントラクトやスクリプトを必要としましたが、AlphaSwarmは自然言語で戦略を入力できるようにします。例えば、「ETH価格が3%上昇したら買い」といった指示を出すと、スマートエージェント群が意図を理解し、市場をリアルタイムで監視し、EthereumやSolanaなど複数のチェーン上で操作を実行します。コーディングの知識がなくても、プロフェッショナルな取引体験を享受できます。
AlphaSwarmの核は、スマートエージェント群の協働にあります。システムは、タスクに応じてデータ分析、戦略生成、実行などさまざまな役割を持つエージェントを自動的に組み合わせ、投票や適応戦略によって意思決定を行います。この群集知能により効率が向上し、戦略の実行もより堅牢で柔軟になります。
市場は刻一刻と変化しますが、AlphaSwarmは強化学習を通じて戦略を絶えず最適化し、チェーン上の信用システムを使ってエージェントのパフォーマン
ETH-0.07%

- 報酬
- いいね
- コメント
- リポスト
- 共有
⚡️ 友友们、AI 安全討論はしばしば原則的な声明に埋もれがちです。偏りを避け、能力を制限し、信頼性を確保するためですが、多くの議論は依然として理論上の段階にとどまっています。
真の課題はすでに目の前にあります。それは推論過程自体の検証可能性です。大規模言語モデル(LLM)の誤りは避けられません。問題は決して偶発的なミスそのものではなく、私たちが判断の論理と根拠を明確に追跡できないことにあります。
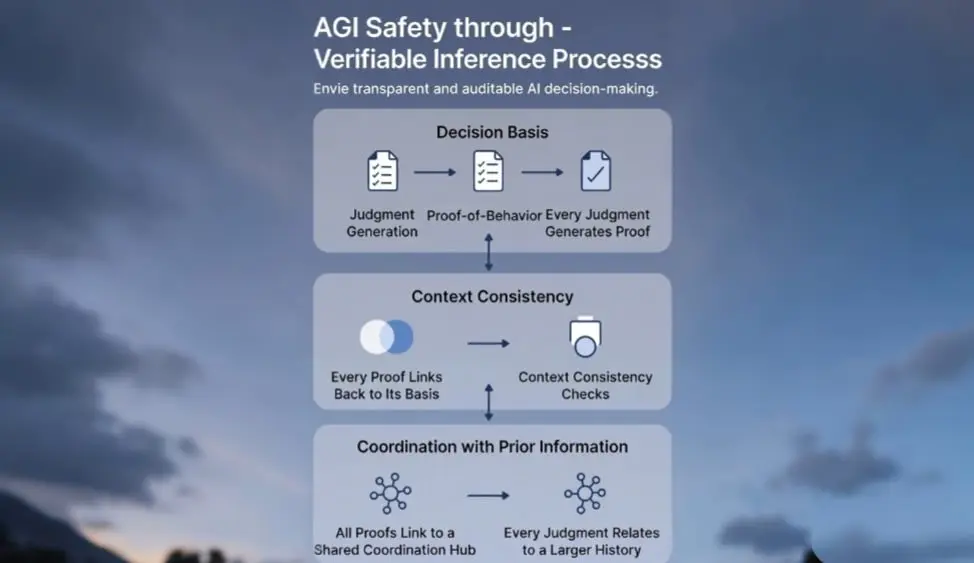
これこそが AGI 安全の核心です:結果を知るだけでなく、「なぜそう判断したのか」を理解することです。推論過程が透明で検証可能なとき、私たちは真に制御し、安全に知能システムを展開できるのです。
ここで、Inference(推論)は異なるアプローチを提供します。これは単にモデルに自己説明をさせるだけでなく、システム構造を通じて、各判断が行動証拠(Proof-of-Behavior)を生成できることを保証します。この証拠は意思決定の根拠、文脈の一貫性、以前の情報との整合性を記録し、検証可能な論理的連鎖を形成します。
さらに進めて、一致性証明(Consistency Proof)はシステム自身が検査できる仕組みです。現在の推論がルールや文脈、過去の判断に沿っているかどうかを確認します。偏りや誤りがあれば、システムはエラーを報告し、問題の根源を追跡できます。これにより、AGIは従来のブラックボッ
原文表示真の課題はすでに目の前にあります。それは推論過程自体の検証可能性です。大規模言語モデル(LLM)の誤りは避けられません。問題は決して偶発的なミスそのものではなく、私たちが判断の論理と根拠を明確に追跡できないことにあります。
これこそが AGI 安全の核心です:結果を知るだけでなく、「なぜそう判断したのか」を理解することです。推論過程が透明で検証可能なとき、私たちは真に制御し、安全に知能システムを展開できるのです。
ここで、Inference(推論)は異なるアプローチを提供します。これは単にモデルに自己説明をさせるだけでなく、システム構造を通じて、各判断が行動証拠(Proof-of-Behavior)を生成できることを保証します。この証拠は意思決定の根拠、文脈の一貫性、以前の情報との整合性を記録し、検証可能な論理的連鎖を形成します。
さらに進めて、一致性証明(Consistency Proof)はシステム自身が検査できる仕組みです。現在の推論がルールや文脈、過去の判断に沿っているかどうかを確認します。偏りや誤りがあれば、システムはエラーを報告し、問題の根源を追跡できます。これにより、AGIは従来のブラックボッ
- 報酬
- いいね
- コメント
- リポスト
- 共有
⚡️ 友人の皆さん、「少ないことは多いこと」。Talusは複雑さを自分たちに引き受け、シンプルさをユーザーに提供します。
エアドロップのプランが直前で調整されると、コミュニティはまず「プロジェクト側の力不足では?」と推測しがちです。しかし、Talusが$yUS Vaultを$US に切り替えるという決断は、まったく逆の賢明さを示しています。重要な局面で思い切って引き算をすることこそ、ユーザーへの最大の誠意です。
複雑をシンプルにすることが、最も効率的なエンパワーメントです。$yUS は利息を生む資産として良いコンセプトですが、ユーザーにとっては理解コストや運用リスクが無形のうちに増してしまいます。パートナーが長期安定を約束できない場合、無理にローンチを続けるのは華やかな冒険に過ぎません。
Talusは$USを直接配布することを選び、一見後退のように見えて、実は選択権と流動性を完全にユーザーへ返しました。仕組みを調べる必要もなく、カストディを心配する必要もありません。価値は明確で、参加の道筋もワンクリックで直感的です。これは妥協ではなく、ユーザー体験を最優先にした精密な調整です。
遅延は、より良い到達のための時もあります。チームによれば、将来的に$yUS はNexusの自動化ワークフローで再構築される可能性もあるとのこと。つまり、一時的な保留は放棄ではなく、依存から脱却し、よりオンチ
原文表示エアドロップのプランが直前で調整されると、コミュニティはまず「プロジェクト側の力不足では?」と推測しがちです。しかし、Talusが$yUS Vaultを$US に切り替えるという決断は、まったく逆の賢明さを示しています。重要な局面で思い切って引き算をすることこそ、ユーザーへの最大の誠意です。
複雑をシンプルにすることが、最も効率的なエンパワーメントです。$yUS は利息を生む資産として良いコンセプトですが、ユーザーにとっては理解コストや運用リスクが無形のうちに増してしまいます。パートナーが長期安定を約束できない場合、無理にローンチを続けるのは華やかな冒険に過ぎません。
Talusは$USを直接配布することを選び、一見後退のように見えて、実は選択権と流動性を完全にユーザーへ返しました。仕組みを調べる必要もなく、カストディを心配する必要もありません。価値は明確で、参加の道筋もワンクリックで直感的です。これは妥協ではなく、ユーザー体験を最優先にした精密な調整です。
遅延は、より良い到達のための時もあります。チームによれば、将来的に$yUS はNexusの自動化ワークフローで再構築される可能性もあるとのこと。つまり、一時的な保留は放棄ではなく、依存から脱却し、よりオンチ

- 報酬
- 1
- コメント
- リポスト
- 共有
⚡️ 皆さん、金融分野からロボティクスまで、新世代のインテリジェントシステムは、単に操作を実行するだけでなく、あらゆる意思決定について説明し証明する能力が求められています。
実行できるだけではもはや十分ではなく、説明責任が新たな基盤となりつつあります。@inference_labs はそのための基礎を提供しています。検証可能な計算パイプラインを通じて、自律的な行動を監査可能で信頼性があり、検証可能な形に変換します。
あらゆる行動が数学的に証明可能で、意思決定の経路も論理的に透明で検証可能となり、自律システムはもはやブラックボックスでも脆弱でもありません。
高価値システムは、エージェントを盲目的に信頼する必要がなくなり、信頼は仮定ではなく証明から生まれます。
これこそが真の自律性を構築する道です。もはやエージェントの行動が正しいことを期待するだけでなく、その推論過程を示す力を持たせるのです。
Inference Labs はインテリジェントオートメーションの変革を支援するだけでなく、説明責任を確立し、将来のインテリジェントシステムの信頼できる基盤を築きます。
@inference_labs #inference @KaitoAI #KAITO
原文表示実行できるだけではもはや十分ではなく、説明責任が新たな基盤となりつつあります。@inference_labs はそのための基礎を提供しています。検証可能な計算パイプラインを通じて、自律的な行動を監査可能で信頼性があり、検証可能な形に変換します。
あらゆる行動が数学的に証明可能で、意思決定の経路も論理的に透明で検証可能となり、自律システムはもはやブラックボックスでも脆弱でもありません。
高価値システムは、エージェントを盲目的に信頼する必要がなくなり、信頼は仮定ではなく証明から生まれます。
これこそが真の自律性を構築する道です。もはやエージェントの行動が正しいことを期待するだけでなく、その推論過程を示す力を持たせるのです。
Inference Labs はインテリジェントオートメーションの変革を支援するだけでなく、説明責任を確立し、将来のインテリジェントシステムの信頼できる基盤を築きます。
@inference_labs #inference @KaitoAI #KAITO

- 報酬
- いいね
- コメント
- リポスト
- 共有
⚡️ 友友たち、取引体験はしばしば細部で成否が決まります。Orderly Network がリリースした SDK v2.8.6 は、まさに細部にこだわったアップデートで、ユーザーの操作をよりスムーズに、そしてより安全にします。
ワンクリック反転は、新しいボタンを増やすのではなく、慌ててポジションをクローズし再度エントリーする手間からあなたを解放します。相場が反転した時に必要なのは、手順ではなくアクションです。
損切りロジックの強化は、予期せぬ事態との境界線を事前に引いておくことです。これは市場の変動を防ぐものではなく、仕組みの不備による余計なコストを防ぎます。安全は運任せであってはなりません。
入出金情報の明確化やAPY表示の精度向上、結局のところ大事なのは「分かりやすさ」です。資金の動きが謎掛けのようであってはならず、収益データが推測であってもいけません。コントロール感は、まず明確な情報から生まれます。
優れたインフラは、しばしば静かです。自らのすごさを声高に叫んだりせず、あなたがほとんど気付かないような細かな違和感をなめらかにします。あなたが出会うかもしれない落とし穴を事前に埋め、ツールの存在を意識させないことが本当のスムーズさだと理解しています。意識は常に市場そのものに向けられるべきです。
これこそがプロフェッショナルの本質かもしれません。頻繁なイノベーションを追い求めるので
ワンクリック反転は、新しいボタンを増やすのではなく、慌ててポジションをクローズし再度エントリーする手間からあなたを解放します。相場が反転した時に必要なのは、手順ではなくアクションです。
損切りロジックの強化は、予期せぬ事態との境界線を事前に引いておくことです。これは市場の変動を防ぐものではなく、仕組みの不備による余計なコストを防ぎます。安全は運任せであってはなりません。
入出金情報の明確化やAPY表示の精度向上、結局のところ大事なのは「分かりやすさ」です。資金の動きが謎掛けのようであってはならず、収益データが推測であってもいけません。コントロール感は、まず明確な情報から生まれます。
優れたインフラは、しばしば静かです。自らのすごさを声高に叫んだりせず、あなたがほとんど気付かないような細かな違和感をなめらかにします。あなたが出会うかもしれない落とし穴を事前に埋め、ツールの存在を意識させないことが本当のスムーズさだと理解しています。意識は常に市場そのものに向けられるべきです。
これこそがプロフェッショナルの本質かもしれません。頻繁なイノベーションを追い求めるので
ORDER-1.19%

- 報酬
- いいね
- コメント
- リポスト
- 共有
⚡️ 友友たち、冷静な市場での粘り強さ、取引量は上下しますが、道のりはまだ長いです。土曜日の相場はいつも静かで、特にビットコインが9万ドルの節目を割ったとき、市場全体が一時的な沈黙に包まれました。
Orderly Networkのデータも例外ではなく、取引量は6516万ドルで前日比44.55%減少、収益は4738ドルでほぼ半減しました。数字は直感的で、上下は市場の常です。
こうした低調な時期にも、2598人の新規ユーザーが参加を選びました。これは偶然ではなく、シグナルです。全体が静かな市場でも、密かに布石を打ち、次のサイクルを待つ人がいます。
私は常に、プロジェクトを観察する際は、そのピーク時の賑わいだけでなく、低迷時の姿勢を重視すべきだと考えています。Orderlyチームは引き続き構築を続け、UCCコンテストも進行中です。賞金総額20万ドル、参加者2544名、累計取引量は7億ドル超、優勝者は5万USDCを独占します。
注目すべきはエコシステム間の連携です。AegisのYUSDをOrderlyで取引すると、ユーザーはAegisトークンの総供給量の0.3%を追加で獲得できます。これは単なる補助金ではなく、DeFiレゴの価値の結びつきであり、細分化された分野を深掘りし、コラボレーションによって効果を拡大しています。業界が成熟するのは、このような繋がりから始まるものです。
コンテスト終了
原文表示Orderly Networkのデータも例外ではなく、取引量は6516万ドルで前日比44.55%減少、収益は4738ドルでほぼ半減しました。数字は直感的で、上下は市場の常です。
こうした低調な時期にも、2598人の新規ユーザーが参加を選びました。これは偶然ではなく、シグナルです。全体が静かな市場でも、密かに布石を打ち、次のサイクルを待つ人がいます。
私は常に、プロジェクトを観察する際は、そのピーク時の賑わいだけでなく、低迷時の姿勢を重視すべきだと考えています。Orderlyチームは引き続き構築を続け、UCCコンテストも進行中です。賞金総額20万ドル、参加者2544名、累計取引量は7億ドル超、優勝者は5万USDCを独占します。
注目すべきはエコシステム間の連携です。AegisのYUSDをOrderlyで取引すると、ユーザーはAegisトークンの総供給量の0.3%を追加で獲得できます。これは単なる補助金ではなく、DeFiレゴの価値の結びつきであり、細分化された分野を深掘りし、コラボレーションによって効果を拡大しています。業界が成熟するのは、このような繋がりから始まるものです。
コンテスト終了

- 報酬
- いいね
- コメント
- リポスト
- 共有
⚡️ 皆さん、AIのデータ・計算力・モデルが徐々に少数の大手企業に集中していく中で、一般の人々は何ができるのでしょうか。受け身で待つのか、それとも新たな道を探すのか。
Talusというプロジェクトは自分たちなりの答えを出しました。AIをオンチェーンリソースにし、誰もが参加・承認・決済できるようにするというものです。
一、なぜ今なのか?
現在のAI分野では、一般の人々にはほとんど発言権がありません。データは大手企業のサーバーにあり、計算力は高額、さらにモデルも厳重に管理されています。Talusが打破しようとしているのはまさにこの独占構造で、AIリソースをオンチェーン化し、所有・流通可能なものにします。
二、なぜMoveを選んだのか?
プロジェクトチームは一般的なEVMを選ばず、基盤としてMove言語を使用しました。その背景には実際のニーズがあります。将来的にAIエージェントが私たちに代わって資産を保有し、高価値な操作を実行することになるため、高いセキュリティと並列処理が求められます。従来のソリューションでは対応が難しいのです。
三、彼らは何を目指すのか?
想像してみてください。DeFiによる自動収益獲得、Intentソリューション、ゲームのAI代理、DAOのガバナンスアシスタント、モデル発行プラットフォーム……これらすべてがTalus上で現実になります。Talusは特定のアプリケーシ
原文表示Talusというプロジェクトは自分たちなりの答えを出しました。AIをオンチェーンリソースにし、誰もが参加・承認・決済できるようにするというものです。
一、なぜ今なのか?
現在のAI分野では、一般の人々にはほとんど発言権がありません。データは大手企業のサーバーにあり、計算力は高額、さらにモデルも厳重に管理されています。Talusが打破しようとしているのはまさにこの独占構造で、AIリソースをオンチェーン化し、所有・流通可能なものにします。
二、なぜMoveを選んだのか?
プロジェクトチームは一般的なEVMを選ばず、基盤としてMove言語を使用しました。その背景には実際のニーズがあります。将来的にAIエージェントが私たちに代わって資産を保有し、高価値な操作を実行することになるため、高いセキュリティと並列処理が求められます。従来のソリューションでは対応が難しいのです。
三、彼らは何を目指すのか?
想像してみてください。DeFiによる自動収益獲得、Intentソリューション、ゲームのAI代理、DAOのガバナンスアシスタント、モデル発行プラットフォーム……これらすべてがTalus上で現実になります。Talusは特定のアプリケーシ

- 報酬
- いいね
- コメント
- リポスト
- 共有
⚡️ フレンたち、ビットコインはもはや新しいものではありませんが、奇妙な現象があります。価値は大きいですが、大部分の時間静かに横たわっています。
2兆ドルの資産プールの中で、実際に流動しているのは1%にも満たない。考えてみてください、これほどの富がほとんど使われていないとは、まさに効率のブラックホールではありませんか。
過去、ビットコインで最も一般的な遊び方は買って放置することでした。人々はこれをデジタルゴールドと呼び、したがってゴールドのような静的で非効率的な特性も当然受け継がれました。
DeFiに流入するBTCは1%未満であり、本質的にはユーザーが怠慢であるのではなく、インフラが不足しているからです:貸出がなく、利回り曲線がなく、リスク価格設定もなく、オンチェーンの信用拡張については言うまでもありません。いわゆるBTCFiは、ずっと願望のレベルにとどまっています。
Lombard(LBTC)が行っていることは、シンプルですが重要です。それは、ビットコインをポジションから資本に変えることです。これにより、担保として使えたり、借りられたり、流通したり、収益を生むことが可能になります。伝統的な金融のありきたりな話に聞こえるかもしれませんが、まさにこれらの構造的な要素が現代の資本市場を数十年支えてきました。ビットコインに欠けているのは次のラウンドのナラティブではなく、この最も基本的な基
原文表示2兆ドルの資産プールの中で、実際に流動しているのは1%にも満たない。考えてみてください、これほどの富がほとんど使われていないとは、まさに効率のブラックホールではありませんか。
過去、ビットコインで最も一般的な遊び方は買って放置することでした。人々はこれをデジタルゴールドと呼び、したがってゴールドのような静的で非効率的な特性も当然受け継がれました。
DeFiに流入するBTCは1%未満であり、本質的にはユーザーが怠慢であるのではなく、インフラが不足しているからです:貸出がなく、利回り曲線がなく、リスク価格設定もなく、オンチェーンの信用拡張については言うまでもありません。いわゆるBTCFiは、ずっと願望のレベルにとどまっています。
Lombard(LBTC)が行っていることは、シンプルですが重要です。それは、ビットコインをポジションから資本に変えることです。これにより、担保として使えたり、借りられたり、流通したり、収益を生むことが可能になります。伝統的な金融のありきたりな話に聞こえるかもしれませんが、まさにこれらの構造的な要素が現代の資本市場を数十年支えてきました。ビットコインに欠けているのは次のラウンドのナラティブではなく、この最も基本的な基

- 報酬
- いいね
- コメント
- リポスト
- 共有
⚡️ 友友たち、Perp Dex が利用可能で、ApeX は本当に加速しています。ApeX の今週の動向を見たとき、最初の反応はこのプラットフォームがとても新しいものを巻き起こしているということです。
他の DeFi は取引体験を CEX のようにする方法を模索している間に、ApeX はすでにワンクリックで全ポジションを決済する機能や逆ポジションの機能をオンチェーン契約に組み込みました。ハイフリークなプレイヤーにとって、1秒の違いが2つの結果を生むことがありますが、それを彼はうまく捉えています。
さらに厳しいのは、本物の金と銀を使った買い戻しで、962.5 万米ドルです。無駄な話はせず、資金で態度を示します。製品のリズムも途切れておらず、Ape Season にはまだ 2300 万ポイントが残っています。MON 永続と連邦準備制度理事会の議長の市場予測が続けてオンラインになります。
それが意図的に全、速、正確を取引の動線に組み込もうとしているのを感じることができ、さらには予測の領域に仕掛けを埋め始めている。Limitlessとの協力が実現すれば、また新たな加速の輪が始まると予想される。
意外なことに、AIコンペティションの結果は、どのモデルが優れているかではなく、誰がAIとより良く協力できるかが競われました。これによって、ApeXの今後のAIツールへの期待が高まりました:ツール自体
他の DeFi は取引体験を CEX のようにする方法を模索している間に、ApeX はすでにワンクリックで全ポジションを決済する機能や逆ポジションの機能をオンチェーン契約に組み込みました。ハイフリークなプレイヤーにとって、1秒の違いが2つの結果を生むことがありますが、それを彼はうまく捉えています。
さらに厳しいのは、本物の金と銀を使った買い戻しで、962.5 万米ドルです。無駄な話はせず、資金で態度を示します。製品のリズムも途切れておらず、Ape Season にはまだ 2300 万ポイントが残っています。MON 永続と連邦準備制度理事会の議長の市場予測が続けてオンラインになります。
それが意図的に全、速、正確を取引の動線に組み込もうとしているのを感じることができ、さらには予測の領域に仕掛けを埋め始めている。Limitlessとの協力が実現すれば、また新たな加速の輪が始まると予想される。
意外なことに、AIコンペティションの結果は、どのモデルが優れているかではなく、誰がAIとより良く協力できるかが競われました。これによって、ApeXの今後のAIツールへの期待が高まりました:ツール自体
MON-10.13%

- 報酬
- いいね
- コメント
- リポスト
- 共有