Купути криптовалюту
Оплачуйте
USD
Швидка покупка
HOT
Купуйте та продавайте криптовалюту через Apple Pay, картки, Google Pay, Банківський переказ тощо
P2P
0 Fees
Нульова комісія, понад 400 способів оплати та зручна купівля й продаж криптовалют
Gate Card
Криптовалютна платіжна картка, що дозволяє здійснювати безперешкодні глобальні транзакції.
Торгівля
Тип торгівлі
Спот
Вільно торгуйте криптовалютою
Alpha
Поінти
Отримуйте перспективні токени в спрощеній ончейн торгівлі
Премаркет
Торгуйте новими токенами до їх офіційного лістингу
Маржа
Збільшуйте свій прибуток за допомогою кредитного плеча
Конвертація та блокова торгівля
0 Fees
Торгуйте будь-яким обсягом без комісій та прослизань
Токени з кредитним плечем
Отримайте швидкий доступ до позицій кредитного плеча
Ф'ючерси
Ф'ючерси
Сотні контрактів розраховані в USDT або BTC
Опціони
HOT
Торгівля ванільними опціонами європейського зразка
Єдиний рахунок
Максимізуйте ефективність вашого капіталу
Демо торгівля
Запуск ф'ючерсів
Підготуйтеся до ф’ючерсної торгівлі
Ф'ючерсні події
Беріть участь у подіях, щоб виграти щедрі винагороди
Демо торгівля
Використовуйте віртуальні кошти для безризикової торгівлі
Earn
Запуск
Інвестиції
Simple Earn
VIP
Заробляйте відсотки за допомогою неактивних токенів
Автоінвестування
Автоматичне інвестування на регулярній основі
Подвійні інвестиції
Купуйте дешево і продавайте дорого, щоб отримати прибуток від коливань цін
Квантовий фонд
VIP
Найкраща команда з управління активами допоможе вам отримати прибуток без клопоту
Криптопозика
0 Fees
Заставте одну криптовалюту, щоб позичити іншу
Центр кредитування
Єдиний центр кредитування
Центр багатства VIP
New
Індивідуальне управління капіталом сприяє зростанню ваших активів
Стейкінг
Стейкайте криптовалюту, щоб заробляти на продуктах PoS
BTC Стейкінг
HOT
Стейкайте BTC та отримуйте 10% APR
Стейкінг ETH
HOT
Стейкайте ETH та отримуйте 6% APR
Випуск GUSD
New
Використовуйте USDT/USDC для випуску GUSD з дохідністю на рівні казначейських облігацій
Софт-стейкінг
Отримуйте винагороди з гнучким стейкінгом
Більше


- Популярні темиДізнатися більше
2.3K Популярність
16.8K Популярність
38.6K Популярність
37K Популярність
2.2K Популярність
- Закріпити
Розкриття трансформера в iPhone: на основі архітектури GPT-2 слово segmenter містить емодзі, створені випускниками MIT
Оригінальне джерело: Qubits
«Секрет» трансформера від Apple розкрили ентузіасти.
На хвилі великих моделей, навіть якщо ви такий консервативний, як Apple, ви повинні згадувати «Трансформер» на кожній прес-конференції.
Наприклад, на цьогорічному WWDC Apple оголосила, що нові версії iOS і macOS матимуть вбудовані мовні моделі Transformer, щоб забезпечити методи введення з можливостями передбачення тексту.
Хлопець на ім'я Джек Кук перевернув бета-версію macOS Sonoma з ніг на голову та дізнався багато свіжої інформації:
Давайте розглянемо докладніше.
На основі архітектури GPT-2
По-перше, давайте розглянемо, які функції мовна модель Apple на основі Transformer може реалізувати на iPhone, MacBook та інших пристроях.
В основному відбивається на способі введення. Власний метод введення Apple, який підтримується мовною моделлю, може використовувати функції прогнозування слів і виправлення помилок.
** **### △Джерело: публікація в блозі Джека Кука
**### △Джерело: публікація в блозі Джека Кука
Модель іноді передбачає кілька наступних слів, але це обмежено ситуаціями, коли семантика речення дуже очевидна, подібно до функції автозаповнення в Gmail.
** **### △Джерело: публікація в блозі Джека Кука
**### △Джерело: публікація в блозі Джека Кука
Так де саме встановлена ця модель? Після деяких глибоких копань брат Кук визначив:
Оскільки:
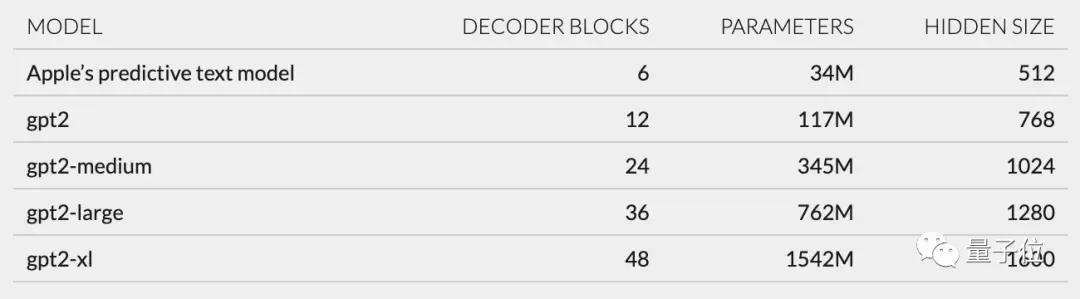
Крім того, на основі структури мережі, описаної в unilm_joint_cpu, я припустив, що модель Apple базується на архітектурі GPT-2:
В основному він включає вбудовування маркерів, кодування позиції, блок декодера та вихідний рівень. Кожен блок декодера має такі слова, як gpt2_transformer_layer_3d.
** **### △Джерело: публікація в блозі Джека Кука
**### △Джерело: публікація в блозі Джека Кука
Виходячи з розміру кожного шару, я також припустив, що модель Apple має приблизно 34 мільйони параметрів, а розмір прихованого шару становить 512. Тобто він менший за найменшу версію GPT-2.
Я вважаю, що це головним чином тому, що Apple хоче модель, яка споживає менше енергії, але може працювати швидко та часто.
Офіційна заява Apple на WWDC полягає в тому, що «кожного натискання клавіші iPhone запускатиме модель один раз».
Однак це також означає, що ця модель передбачення тексту не дуже добре продовжує речення або абзаци повністю.
** **### △Джерело: публікація в блозі Джека Кука
**### △Джерело: публікація в блозі Джека Кука
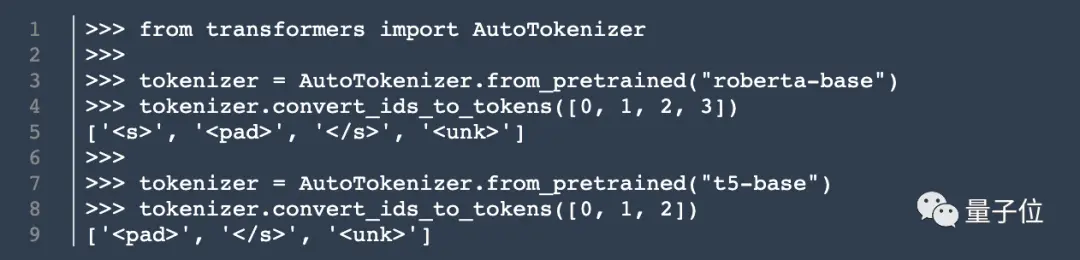
Крім архітектури моделі, Кук також розкопав інформацію про токенизатор.
У unilm.bundle/sp.dat він знайшов набір із 15 000 токенів, варто зазначити, що він містить 100 емодзі.
Кухар розкриває Кука
Хоча цей кухар не кухар, мій допис у блозі все одно привернув багато уваги, щойно його опублікували.
Раніше він стажувався в NVIDIA, зосереджуючись на дослідженні мовних моделей, таких як BERT. Він також є старшим інженером з досліджень і розробок обробки природної мови в The New York Times.
Отже, його одкровення також викликало у вас якісь думки? Ласкаво просимо поділитися своїми думками в області коментарів ~
Оригінальне посилання: