Trade
Trading Type
Spot
Trade crypto freely
Alpha
Points
Get promising tokens in streamlined on-chain trading
Pre-Market
Trade new tokens before they are officially listed
Margin
Magnify your profit with leverage
Convert & Block Trading
0 Fees
Trade any size with no fees and no slippage
Leveraged Tokens
Get exposure to leveraged positions simply
Futures
Futures
Hundreds of contracts settled in USDT or BTC
Options
HOT
Trade European-style vanilla options
Unified Account
Maximize your capital efficiency
Demo Trading
Futures Kickoff
Get prepared for your futures trading
Futures Events
Participate in events to win generous rewards
Demo Trading
Use virtual funds to experience risk-free trading
Earn
Launch
Investment
Simple Earn
VIP
Earn interests with idle tokens
Auto-Invest
Auto-invest on a regular basis
Dual Investment
Buy low and sell high to take profits from price fluctuations
Quant Fund
VIP
Top asset management team helps you profit without hassle
Crypto Loan
0 Fees
Pledge one crypto to borrow another
Lending Center
One-Stop Lending Hub
VIP Wealth Hub
New
Customized wealth management empowers your assets growth
Staking
Stake cryptos to earn in PoS products
BTC Staking
HOT
Stake BTC and earn 10% APR
ETH Staking
HOT
Stake ETH and earn 6% APR
GUSD Minting
New
Use USDT/USDC to mint GUSD for treasury-level yields
Soft Staking
Earn rewards with flexible staking
More


- Trending TopicsView More
398 Popularity
15.9K Popularity
37.3K Popularity
36.7K Popularity
2.2K Popularity
- Pin
iPhone'daki Transformer'ı Ortaya Çıkarıyoruz: GPT-2 mimarisini temel alan segmenter kelimesi, MIT mezunları tarafından üretilen emojileri içeriyor
Orijinal kaynak: Qubits
Apple'ın Transformer ürününün "sırrı" meraklılar tarafından ortaya çıktı.
Büyük model dalgasında, Apple kadar muhafazakar olsanız bile her basın toplantısında "Transformer"dan bahsetmelisiniz.
Örneğin, bu yılki WWDC'de Apple, iOS ve macOS'un yeni sürümlerinin, metin tahmin yeteneklerine sahip giriş yöntemleri sağlamak için yerleşik Transformer dil modellerine sahip olacağını duyurdu.
Jack Cook adında bir adam, macOS Sonoma beta'yı alt üst etti ve pek çok yeni bilgi keşfetti:
Daha fazla ayrıntıya göz atalım.
GPT-2 mimarisine dayalıdır
Öncelikle Apple’ın Transformer tabanlı dil modelinin iPhone, MacBook ve diğer cihazlarda hangi işlevleri gerçekleştirebileceğine bakalım.
Esas olarak giriş yöntemine yansır. Dil modeli tarafından desteklenen Apple'ın kendi giriş yöntemi, kelime tahmini ve hata düzeltme işlevlerini gerçekleştirebilir.
** **### △Kaynak: Jack Cook blog yazısı
**### △Kaynak: Jack Cook blog yazısı
Model bazen birden fazla yaklaşan kelimeyi tahmin eder, ancak bu, Gmail'deki otomatik tamamlama işlevine benzer şekilde, cümlenin anlambiliminin çok açık olduğu durumlarla sınırlıdır.
** **### △Kaynak: Jack Cook blog yazısı
**### △Kaynak: Jack Cook blog yazısı
Peki bu model tam olarak nereye kurulu? Biraz derinlemesine araştırma yaptıktan sonra Cook Kardeş şunu belirledi:
Çünkü:
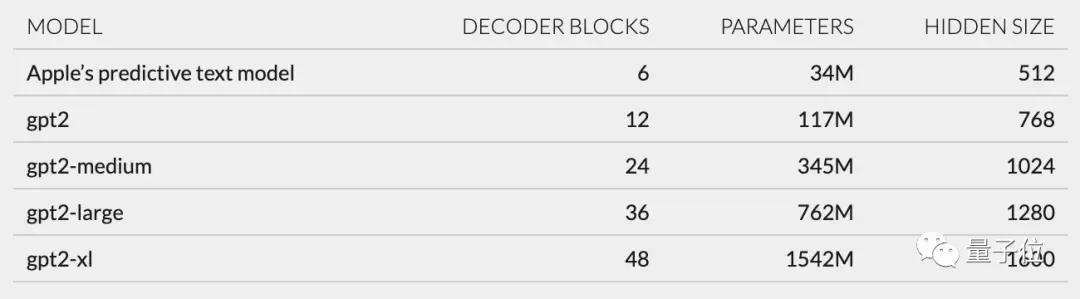
Ayrıca unilm_joint_cpu'da açıklanan ağ yapısına dayanarak Apple modelinin GPT-2 mimarisini temel aldığını tahmin ettim:
Temel olarak belirteç yerleştirmeleri, konum kodlamayı, kod çözücü bloğunu ve çıktı katmanını içerir.Her kod çözücü bloğunda gpt2_transformer_layer_3d gibi kelimeler bulunur.
** **### △Kaynak: Jack Cook blog yazısı
**### △Kaynak: Jack Cook blog yazısı
Her katmanın boyutuna göre Apple modelinin yaklaşık 34 milyon parametreye sahip olduğunu ve gizli katman boyutunun 512 olduğunu tahmin ettim. Yani GPT-2'nin en küçük versiyonundan daha küçüktür.
Bunun esas olarak Apple'ın daha az güç tüketen ancak hızlı ve sık çalışabilen bir model istemesinden kaynaklandığına inanıyorum.
Apple'ın WWDC'deki resmi açıklaması şöyle: "Bir tuşa her tıklandığında, iPhone modeli bir kez çalıştıracaktır."
Ancak bu aynı zamanda bu metin tahmin modelinin cümleleri veya paragrafları tamamen devam ettirme konusunda pek iyi olmadığı anlamına da gelir.
** **### △Kaynak: Jack Cook blog yazısı
**### △Kaynak: Jack Cook blog yazısı
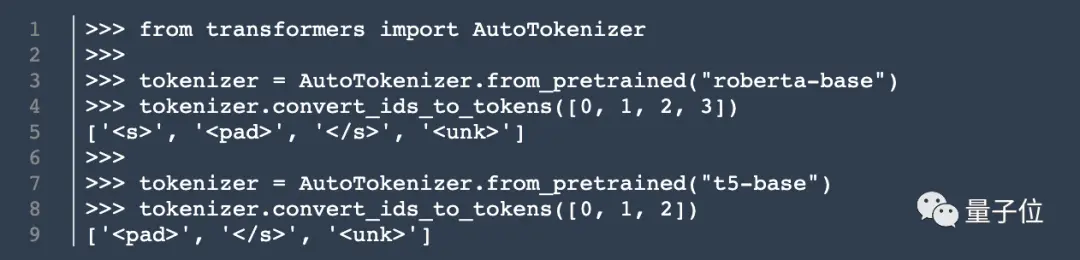
Cook, model mimarisine ek olarak tokenizer hakkında da bilgi topladı.
unilm.bundle/sp.dat adresinde 15.000 token içeren bir set buldu. Bu setin 100 emoji içerdiğini belirtmekte fayda var.
Aşçı, Aşçı'yı ortaya çıkarır
Bu Aşçı aşçı olmasa da blog yazım yayınlanır yayınlanmaz yine de oldukça ilgi gördü.
Daha önce NVIDIA'da staj yaparak BERT gibi dil modellerinin araştırılmasına odaklanmıştı. Aynı zamanda The New York Times'ta doğal dil işleme alanında kıdemli araştırma ve geliştirme mühendisidir.
Peki onun bu vahiy sizde de bazı düşünceleri tetikledi mi? Görüşlerinizi yorum alanında paylaşmaya hoş geldiniz~
Orijinal bağlantı: