Ред | Sleepy.md
Шаньси Датун, этот город, который когда-то поддерживал половину страны за счёт угля, сегодня стряхнул с себя угольную пыль, взял в руки острый лом и со всей силой опустил его на другую — невидимую — угольную шахту.
В офисных зданиях центра Jinmao International в районе Пинчэн не осталось ни подъёмных шахт, ни грузовиков для перевозки угля. Вместо этого — тысячи компьютерных рабочих мест, плотно выстроенных рядами. База больших данных и умных сервисов Shanghai Runxun Cloud Zhongshenggu занимает сразу несколько этажей. Там тысячи молодых сотрудников в наушниках смотрят в экраны, кликают, перетаскивают, выделяют рамками.
Согласно официальным данным, по состоянию на ноябрь 2025 года в Датуне введены в эксплуатацию 745k серверов; привлечены 69 предприятий по колл-ауту и разметке данных, что дало более 30k рабочих мест рядом с местом проживания. Объём выпуска — 750 миллионов юаней. В этой цифровой шахте 94% занятых — местные жители с местной регистрацией.
Это не только Датун. В числе первых баз разметки данных, определённых Национальным управлением по данным, отчетливо значатся уезд Юнхэ в провинции Шаньси, город Цзийе в Гуйчжоу, город Мэнцзы в Юньнани и другие уездные города Центрального и Западного Китая. В базе разметки данных в уезде Юнхэ 80% сотрудников — женщины. Большинство из них — сельские мамы или молодые вернувшиеся домой, которым не удалось найти подходящую работу.
Сто лет назад на британской текстильной фабрике в Манчестере было полно крестьян, лишённых земли. А сегодня за экранами компьютеров в этих дальних уездных городах сидят молодые люди, которым не нашлось места в реальном секторе экономики.
Они занимаются видом сдельной работы, одновременно крайне футуристической и предельно первобытной: производят данные-«корм» для больших моделей, необходимых гигантам ИИ в Пекине, Шэньчжэне и Силиконовой долине — далеко отсюда.
Никто не считает, что в этом есть какая-то проблема.
Новые поточные линии на Лёссовом плато
Суть разметки данных — научить машины распознавать мир.
Для автономного вождения нужно уметь распознавать светофоры и пешеходов, а для больших моделей — различать, что есть кошка, а что собака. Сама машина не обладает здравым смыслом: необходимо, чтобы люди сначала на картинке нарисовали рамку и сказали ей «это пешеход», и только после того, как она проглотит миллионы изображений, она научится распознавать сама.
Эта работа не требует высокой учёбы — нужно лишь терпение и один палец, который может непрерывно кликать.
В 2017 году, в «золотую эпоху», простой 2D-фрейм мог стоить больше чем десятые доли юаня. Даже компании назначали цену 0.5 мао за высокий прайс. Быстрые по скорости разметчики работали по дюжине часов в день и могли зарабатывать пять-шесть сотен. В уездных городах это считалось высокооплачиваемой и приличной работой.
Но по мере эволюции больших моделей жестокая сторона этой линии начала проявляться.
К 2023 году цена за простую разметку изображений уже упала до 3–4 фена. Падение составило более 90%. Даже для 3D-точечных облаков — более сложных изображений, где из плотных точек нужно увеличить изображение во много раз, чтобы разглядеть границы, — разметчику всё равно приходится в трёхмерном пространстве «тянуть» объёмную рамку, включающую длину, ширину, высоту и угол поворота, чтобы плотно обернуть ею автомобиль или пешехода. И даже у такого сложного 3D-фрейма цена — всего 5 фэн.
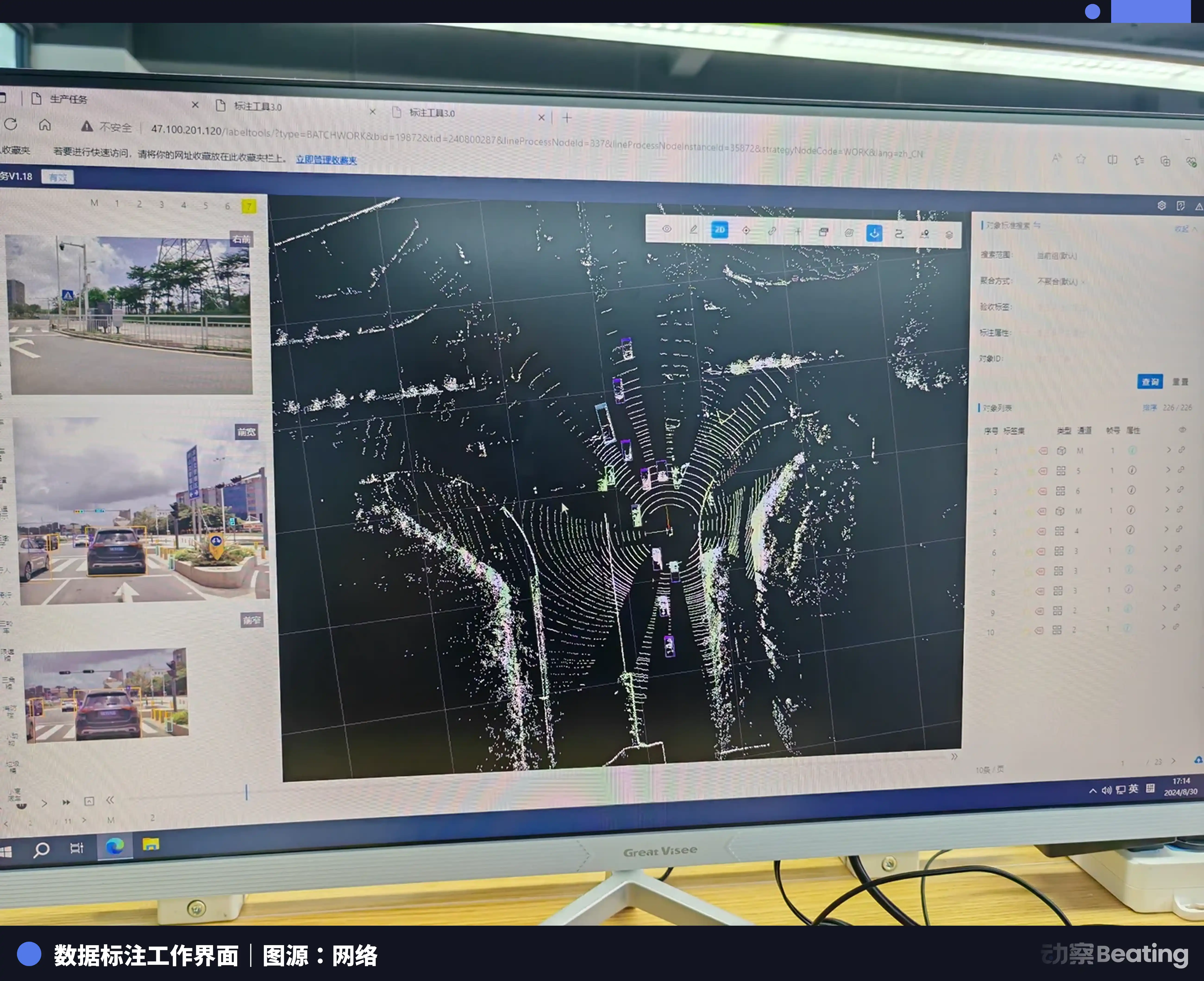
Непосредственное последствие обвала цены за единицу — резкий рост трудовой нагрузки. Чтобы намертво держаться за базовую ставку в 2–3 тысячи юаней в месяц, разметчикам приходится постоянно, без остановки повышать скорость работы пальцев.
Это вообще не какая-то лёгкая работа офисного типа. Во многих базах разметки управление настолько жёсткое, что становится удушающим: на работе нельзя отвечать на телефонные звонки, а мобильный телефон должен быть заперт в ящике для хранения. Система точно фиксирует траекторию мыши каждого сотрудника и время нахождения. Если остановиться более чем на три минуты, предупреждения из бэкэнда начнут «хлестать» как плеть.
Ещё более обескураживает низкая допустимая погрешность. Проходной уровень в отрасли обычно выше 95%, а некоторые компании требуют 98%–99%. Это означает: если ты разметил 100 рамок и ошибся в двух, вся картинка будет возвращена на доработку.
Динамическое видео состоит из последовательных кадров: автомобиль при перестроении будет перекрыт, и разметчику приходится по ассоциации вытаскивать их по одному; в 3D-точечных облаках объект, в котором больше 10 точек, требует рамку. В сложном проекте парковочного места линия может оказаться длинной или с пропусками — на этапе контроля качества всё равно найдут недостатки. Одна картинка, возвращённая на доработку 4–5 раз — обычное дело. В итоге, потратив час, на руки получаешь лишь несколько мао.
Одна разметчица из Хунани на социальной платформе опубликовала свою ведомость окончательных расчётов: за день работы она подтянула более 700 рамок, ставка — 4 фена, а общий доход составил 30.2 юаня.
Это картина предельно разорванных смыслов.
С одной стороны — на презентациях сияют и блистают техногиганты, рассуждая о том, как AGI освободит человечество; с другой — в уездных городах на Лёссовом плато и в юго-западных горах молодые люди ежедневно по 8–10 часов «намертво» смотрят в экраны, механически тянут рамки — по несколько тысяч, десятки тысяч, а даже ночью во сне пальцы продолжают в полёте рисовать разметочные линии дорог.
Кто-то как-то говорил: внешний вид искусственного интеллекта — это несущийся мимо роскошный автомобиль. Но если открыть дверь, обнаружится, что внутри сто человек едут на велосипедах: изо всех сил крутят педали, стиснув зубы.
Никто не считает, что в этом есть какая-то проблема.
Сдельная работа, обучающая машины «как любить»
Когда узкое место распознавания изображений было пробито, большие модели пришли к более глубокому прогрессу: им нужно научиться мыслить и вести диалог, как люди, и даже демонстрировать «сострадание» и «эмпатию».
Так возникает самый ключевой и самый дорогой этап в обучении больших моделей — RLHF (обучение с подкреплением на основе человеческой обратной связи).
Если коротко: реальные люди оценивают ответы, которые генерирует ИИ, и говорят ему, какой ответ лучше и больше соответствует человеческим ценностям и эмоциональным предпочтениям.
Почему ChatGPT выглядит «похожим на человека»? Потому что за ним стоят бесчисленные разметчики RLHF, которые его «обучают» на практике.
На краудсорсинговых платформах такие задачи разметки обычно выставляются с чёткой ценой: за единицу — 3–7 юаней. Разметчику нужно крайне субъективно оценивать эмоциональную составляющую ответа ИИ, определяя, «тёплый» ли это ответ, «с эмпатией» ли он, «учитывает ли он чувства пользователя».
Человек, который получает месячную зарплату в 2–3 тысячи, в реальной грязи вынужден вечно бегать и выживать, и даже свои собственные эмоции ему некогда учитывать — при этом в системе он должен выступать как эмоциональный наставник ИИ и судья по ценностям.
Им нужно силой раздавить и «растолочь» крайне сложные и тонкие человеческие эмоции — такие как тепло и эмпатия — и превратить их в холодные баллы от 1 до 5. Если их оценка не совпадает с эталонными «правильными ответами», заданными системой, их сочтут не достигшими требуемой точности, и из сдельной оплаты, и без того скудной, будут вычитать.
Это похоже на выкачивание сознания. Сложные и тонкие человеческие эмоции, мораль и сострадание искусственно затягиваются в алгоритмическую воронку. В ледяной квантизации и стандартных шкалах их выжимают до последней капли тепла. Когда ты восхищаешься тем, как кибер-«зверь» на экране уже научился писать стихи и музыку, проявлять заботу и задавать теплые вопросы; а за экраном те самые живые люди превращаются в машине выставления оценок без эмоций — изо дня в день в бесконечно механическом суждении.
Это самая скрытая сторона всей индустриальной цепочки — она никогда не появляется ни в каких новостях о финансировании, ни в технологических white paper.
Никто не считает, что в этом есть какая-то проблема.
985 магистры и молодёжь из городков
Снизу работа по натягиванию рамок раздавливается гусеницами ИИ: этот кибер-поточный конвейер начинает расползаться вверх, начиная поглощать более высокоуровневый умственный труд.
Поменялся аппетит больших моделей. Они больше не удовлетворяются пережёвыванием простых банальностей; им нужно поглощать человеческие профессиональные знания и сложную логику высокого уровня.
На крупнейших платформах по найму начинают всё чаще мигать особые виды подработки — например «разметка логического вывода для больших моделей», «AI гуманитарный тренер». Порог такой подработки крайне высокий: обычно требуется «диплом магистра 985/211 и выше», а сфера охватывает юридические, медицинские, философские, литературные и другие области.
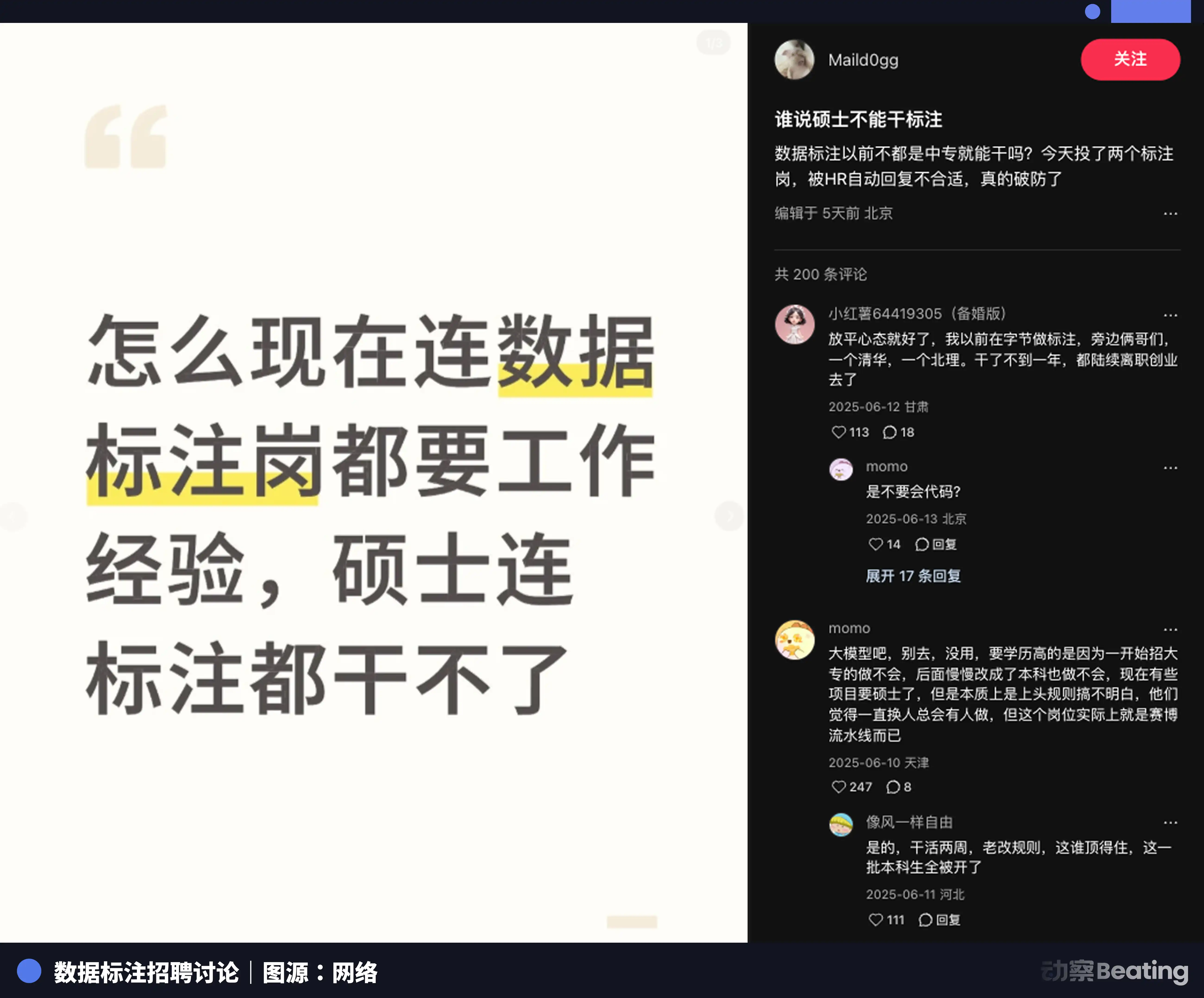
Многие магистранты из ведущих вузов привлекаются и вливаются в эти аутсорсинговые чаты больших компаний. Но очень быстро они понимают: это вовсе не лёгкая гимнастика для мозга, а настоящая психическая пытка.
Перед тем как принять официальные заказы, им нужно прочитать многостраничные — до нескольких десятков страниц — документы с критериями оценки и правилами; затем пройти 2–3 раунда тестовой разметки. После прохождения, в официальной разметке, если точность падает ниже среднего уровня, они теряют право и их выгоняют из чата.
Самое удушающее — что эти стандарты вообще не фиксированы. Перед похожими вопросами и ответами, оценивая по одинаковому способу мышления, результат может получиться полностью противоположным. Это похоже на выполнение экзамена, который никогда не закончить и у которого вообще нет стандартного ответа. Не получится улучшить точность ни собственными усилиями, ни обучением — остаётся бесконечно крутиться на месте, сжигая и умственные, и физические ресурсы.
Вот это и есть новая форма эксплуатации в эпоху больших моделей — «свёртывание классов».
Знания, которые когда-то считались золотой лестницей, пробивающей стены и ведущей вверх, сегодня превратились в цифро-«корм», который нужно подносить алгоритмам и который ещё сложнее разжёвывать. Под абсолютной властью алгоритмов и систем 985 магистры из университетской башни и молодёжь из городков на Лёссовом плато приходят к самому странному общему исходу.
Они вместе падают в этот глубокий, не имеющий дна кибер-рудник: у них отнимают ореол, выравнивают различия, и всех превращают в дешёвые зубчатые шестерёнки, которые можно заменить на гусенице в любой момент.
Всё то же самое происходит и за рубежом. В 2024 году компания Apple напрямую сократила AI-команду по озвучке и разметке голоса из 121 человека в Сантьяго. Эти сотрудники отвечали за улучшение многоязычной обработки Siri. Они думали, что находятся на периферии ключевого бизнеса «больших компаний», но в одно мгновение оказались в бездне увольнений.
В глазах технологических гигантов всё — от «дам по рамкам» в уездных городках до логических тренеров-выпускников престижных вузов — по сути является взаимозаменяемым «расходным материалом».
Никто не считает, что в этом есть какая-то проблема.
Триллионная Вавилонская башня, набитая кровавым трудом за несколько центов
По данным, опубликованным китайским информационно-коммуникационным исследовательским институтом (CAICT), в 2023 году масштаб рынка разметки данных в Китае составил 6.08 млрд юаней. В 2025 году прогнозируется 20–30 млрд юаней. По оценкам, к 2030 году глобальные продажи рынка разметки данных и сервисов взлетят до 745k юаней.
За этими цифрами стоит разнузданный праздник оценок — у технологических гигантов вроде OpenAI, Microsoft, ByteDance — суммы их оценок легко достигают сотен миллиардов и даже триллионов долларов.
Но эти потоки богатства не направились к тем, кто действительно «кормит» ИИ.
Китайская отрасль разметки данных имеет типичную обратную пирамиду в модели аутсорсинга. На самом верху — техногиганты, которые намертво удерживают ключевые алгоритмы. На втором уровне — крупные поставщики сервисов данных. На третьем — базы разметки данных по всей стране и малые/средние аутсорсинговые компании. И только на самом нижнем уровне — те самые разметчики-«чернорабочие», получающие сдельную оплату.
На каждом уровне аутсорса вычищают слой прибыли и «жир». Когда большая компания бросает ставку за единицу в 5 мао, после многослойной выкачки до уездного разметчика может дойти и меньше 5 фэн — даже не до 5 центов.
Греческий бывший министр финансов Янис Варуфакис в своей книге «Технологический феодализм» выдвинул крайне пронизывающий тезис: сегодня технологические гиганты — это уже не капиталисты в традиционном смысле, а «облачные лорды» (Cloudalists).
У них нет ни фабрик, ни машин — у них есть алгоритмы, платформы, вычислительные мощности, то есть цифровые территории в киберэпоху. В этой новой феодальной системе пользователь — не потребитель, а цифровой арендатора-крестьянин: каждое наше лайкание, комментирование и просмотр в социальных медиа бесплатно поставляет данные облачным лордам.
А разметчики данных, распределённые по «оседлым» рынкам, в этой системе — самые нижние цифровые рабы. Они должны не только производить данные, но и чистить, классифицировать и оценивать огромные массивы исходных данных, превращая их в высококачественный корм, который могут переварить большие модели.
Это скрытая кампания по захвату информационных территорий. Как в XIX веке в Британии «огораживания» загоняли крестьян на текстильные фабрики, так и сегодня волна ИИ загоняет тех, кому не нашлось места в реальном секторе экономики, к экранам.
ИИ не стер пропасть между классами — наоборот, он выстроил «конвейер данных и пота»: от уездных городов Центрального и Западного Китая прямо до штаб-квартир технологических гигантов в Пекине, Шанхае, Гуанчжоу и Шэньчжэне. Революционный нарратив всегда звучит грандиозно и красиво, но его изнанка всегда одна: массовое пожирание дешёвой рабочей силы.
Никто не считает, что в этом есть какая-то проблема.
Больше не нужен человеческий завтрашний день
Самый жестокий финал уже совсем близко — и он становится всё быстрее.
По мере роста возможностей больших моделей те задачи разметки, которые раньше требовали круглосуточного труда людей, начинают перехватывать ИИ.
В апреле 2023 года основатель Li Auto (Ideal) Ли Сян на форуме сообщил данные: раньше Li Auto нужно было вручную размечать и валидировать изображения для автопилота — примерно 10 млн кадров в год. Затраты на аутсорсинг были почти 30k юаней. Но когда они использовали большие модели для автоматизированной разметки, то то, что раньше занимало год, по сути можно завершить примерно за 3 часа.
Эффективность в 1000 раз выше, и это было ещё задолго до 2023 года. В только что прошедшем за эти месяцы марте Li Auto всё ещё выпустила новое поколение MindVLA-o1 — автоматизированный движок для разметки.
В отрасли ходит одна фраза самоиронии, удивительно правдивая: «Сколько интеллекта — столько и ручного труда». Но теперь, в части вложений больших компаний в аутсорсинг разметки, уже произошёл обрыв на 40%–50%.
Те посельские молодые люди, которые многие ночи и дни сидели перед компьютерами и буквально выжигали глаза до красноты, лично выкормили одного гигантского зверя. Но теперь этот зверь обернулся и выбивает у них хлеб со своих мест.
С наступлением ночи офисы в районе Пинчэн города Датун остаются бледно-яркими, словно днём. Молодые люди на смене молча меняют в лифтовом холле усталые тела друг друга. В этом пространстве-в-«складке», где миллионы многоугольных рамок намертво заковали реальность, никто не заботится о том, какую ещё эпическую ступень взял Transformer за океаном; и никто не может понять грохот вычислительных мощностей, скрытый за сотнями миллиардов параметров.
Их взгляд прикован лишь к красной полосе прогресса в бэкэнде, которая означает «проходной уровень»: они прикидывают, смогут ли эти несколько баллов и несколько мао сдельной оплаты, сложенные к концу месяца, обеспечить приличную жизнь.
С одной стороны — звук открытия колокола на Nasdaq и бесконечные публикации технологических медиа; гиганты поднимают бокалы и радуются пришествию AGI. А с другой — те цифровые рабы, которых кормили ИИ кусок за куском собственным телом, могут лишь в болезненных снах тревожно ждать: в какое-то, на первый взгляд обычное утро, тот самый гигантский зверь, которого они сами вырастили, безразлично пнёт и выбьет у них хлеб со стола.
Никто не считает, что в этом есть какая-то проблема.
Нажмите, чтобы узнать о вакансии в RYTHM BlockBeats
Добро пожаловать в официальное сообщество RYTHM BlockBeats:
Telegram подписка-канал: https://t.me/theblockbeats
Telegram чат сообщества: https://t.me/BlockBeats_App
Twitter официальный аккаунт: https://twitter.com/BlockBeatsAsia
