Comprar Cripto
Pagar com
USD
Compra rápida
HOT
Compre e venda criptomoedas através da Apple Pay, cartões, Google Pay, transferências bancárias e muito mais
P2P
0 Fees
Taxas zero, mais de 400 opções de pagamento e compra e venda fácil de criptomoedas
Cartão Gate
Cartão de pagamento de criptomoedas, que permite transações globais sem falhas.
Negociar
Tipo de negociação
Negociação à Vista
Negoceie criptomoedas livremente
Alpha
Pontos
Obtenha tokens promissores numa negociação simplificada on-chain
Pré-mercado
Negoceie novos tokens antes de serem oficialmente listados
Margem
Aumente o seu lucro com a alavancagem
Conversão e negociação em blocos
0 Fees
Opere qualquer volume sem tarifas nem derrapagem
Tokens Alavancados
Obtenha exposição a posições alavancadas de uma forma simples
Futuros
Futuros
Centenas de contratos liquidados em USDT ou BTC
Opções
HOT
Negoceie Opções Vanilla ao estilo europeu
Conta Unificada
Maximize a eficiência do seu capital
Negociação de demonstração
Arranque dos futuros
Prepare-se para a sua negociação de futuros
Eventos de futuros
Participe em eventos para ganhar recompensas generosas
Negociação de demonstração
Utilize fundos virtuais para experimentar uma negociação sem riscos
Ganhar
Lançamento
Investimento
Simple Earn
VIP
Ganhe juros com tokens inativos
Investimento automático
Invista automaticamente de forma regular.
Investimento Duplo
Compre na baixa e venda na alta para obter lucros com as flutuações de preços
Fundo Quant
VIP
A melhor equipa de gestão de ativos ajuda-o a lucrar sem complicações
Empréstimo de criptomoedas
0 Fees
Dê em garantia uma criptomoeda para pedir outra emprestada
Centro de empréstimos
Centro de empréstimos integrado
Centro de Património VIP
New
A gestão personalizada do património potencia o crescimento dos seus ativos
Staking
Faça staking de criptomoedas para ganhar em produtos PoS
Staking de BTC
HOT
Faça staking de BTC e ganhe 10% de TAEG
Staking de ETH
HOT
Faça staking de ETH e ganhe 6% de TAEG
Cunhagem de GUSD
New
Utilize USDT/USDC para cunhar GUSD y obter rendimentos ao nível do Tesouro
Staking suave
Ganhe recompensas com staking flexível
Mais


- Tópicos em destaqueVer mais
16.7K Popularidade
25K Popularidade
48.6K Popularidade
36.8K Popularidade
2.7K Popularidade
- Pino
Revelando o Transformer no iPhone: Baseado na arquitetura GPT-2, a palavra segmentador contém emoji, produzido por ex-alunos do MIT
Fonte original: Qubits
O “segredo” do Transformer da Apple foi revelado por entusiastas.
Na onda dos modelos grandes, mesmo que você seja tão conservador quanto a Apple, deve mencionar “Transformer” em todas as coletivas de imprensa.
Por exemplo, na WWDC deste ano, a Apple anunciou que as novas versões do iOS e macOS terão modelos de linguagem Transformer integrados para fornecer métodos de entrada com recursos de previsão de texto.
Um cara chamado Jack Cook virou o beta do macOS Sonoma de cabeça para baixo e descobriu muitas informações novas:
Vamos dar uma olhada em mais detalhes.
Baseado na arquitetura GPT-2
Primeiro, vamos revisar quais funções o modelo de linguagem baseado em Transformer da Apple pode implementar no iPhone, MacBook e outros dispositivos.
Refletido principalmente no método de entrada. O próprio método de entrada da Apple, suportado pelo modelo de linguagem, pode realizar funções de previsão de palavras e correção de erros.
** **### △Fonte: postagem do blog Jack Cook
**### △Fonte: postagem do blog Jack Cook
O modelo às vezes prevê várias palavras futuras, mas isso é limitado a situações em que a semântica da frase é muito óbvia, semelhante à função de preenchimento automático do Gmail.
** **### △Fonte: postagem do blog Jack Cook
**### △Fonte: postagem do blog Jack Cook
Então, onde exatamente esse modelo está instalado? Depois de pesquisar profundamente, o irmão Cook determinou:
Porque:
Além disso, com base na estrutura de rede descrita em unilm_joint_cpu, especulei que o modelo Apple é baseado na arquitetura GPT-2:
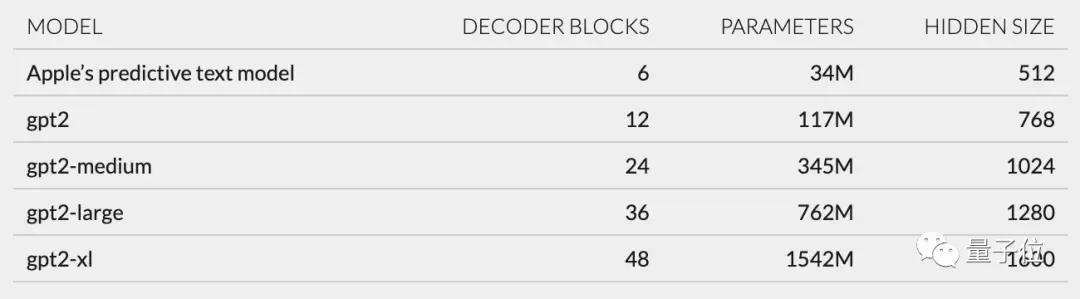
Inclui principalmente incorporações de token, codificação de posição, bloco decodificador e camada de saída. Cada bloco decodificador possui palavras como gpt2_transformer_layer_3d.
** **### △Fonte: postagem do blog Jack Cook
**### △Fonte: postagem do blog Jack Cook
Com base no tamanho de cada camada, também especulei que o modelo Apple tem aproximadamente 34 milhões de parâmetros e o tamanho da camada oculta é 512. Ou seja, é menor que a menor versão do GPT-2.
Acredito que isso se deva principalmente ao fato de a Apple querer um modelo que consuma menos energia, mas que possa funcionar com rapidez e frequência.
A declaração oficial da Apple na WWDC é que “cada vez que uma tecla é clicada, o iPhone executará o modelo uma vez”.
No entanto, isso também significa que este modelo de previsão de texto não é muito bom para continuar frases ou parágrafos completamente.
** **### △Fonte: postagem do blog Jack Cook
**### △Fonte: postagem do blog Jack Cook
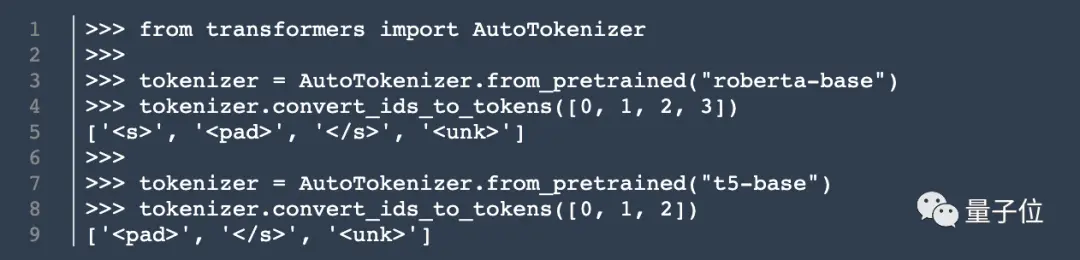
Além da arquitetura do modelo, Cook também desenterrou informações sobre o tokenizer.
Ele encontrou um conjunto de 15.000 tokens em unilm.bundle/sp.dat. Vale ressaltar que ele contém 100 emojis.
Cook revela Cook
Embora este cozinheiro não seja cozinheiro, meu post no blog ainda atraiu muita atenção assim que foi publicado.
Anteriormente, estagiou na NVIDIA, com foco na pesquisa de modelos de linguagem como BERT. Ele também é engenheiro sênior de pesquisa e desenvolvimento para processamento de linguagem natural no The New York Times.
Então, a revelação dele também despertou alguns pensamentos em você? Bem-vindo a compartilhar suas opiniões na área de comentários ~
Links originais: