关于以太坊虚拟机(EVM)的性能
在以太坊主网上的每一个操作都要花费一定的 Gas,如果我们把跑基础应用所需的计算量都放在链上,要么 App 会崩溃,要么用户会破产。
这催生了 L2 :OPRU 引入了排序器来捆绑一堆交易,然后提交到主网上。这不仅有助于 app 承接以太坊的安全性,同时也给予了用户更好的体验。用户可以更快地提交交易,手续费也更加便宜了。虽然操作变得便宜了,但它仍然使用原生 EVM 作为执行层。和 ZK Rollups 类似,Scroll、Polygon zkEVM 使用或将使用基于 EVM 的 zk 电路,zk Proof 将在其证明器上进行的每一笔交易或者一大包交易中生成。虽然这能让开发者建立 "全链上 "的应用程序,但它是否仍能高效且经济地运行高性能的应用程序呢?
这些高性能应用都有哪些?
人们首先想到的是游戏、链上订单簿、Web3 社交、机器学习、基因组建模等。所有这些都需要大计算量,在 L2 上运行也会非常昂贵。EVM 的另一个问题是,计算的速度和效率不如现在的其他系统,如SVM (Sealevel Virtual Machine)。
虽然 L3 EVM 可以使计算更便宜,但 EVM 本身的结构可能不是执行高计算的最佳方式,因为它无法计算并行运算。在上面每建一个新的层的时候,为了保持去中心化的精神,就需要建立新的基础设施(新的节点网络),这仍然需要同样数量的提供者来扩展,或者是一组全新的节点提供者(个人/企业)来提供资源,或者两者都需要。
因此,每当更先进的解决方案被建立时,现有的基础设施就要被升级,或者在上面建立一个新的层。为了解决这个问题,我们需要一个后量子安全、去中心化、无需信任、高性能的计算基础设施,可以真正高效地使用量子算法为去中心化的应用进行计算。
像 Solana、Sui 和 Aptos 这样的 alt-L1s 能够实现并行执行,但由于市场情绪,流动性短缺市场上缺乏开发人员,他们不会对以太坊产生挑战。因为缺乏信任,而且以太坊用网络效应建立的护城河是里程碑式的。到目前为止,ETH/EVM 的杀手并不存在。这里的问题是,为什么所有的计算都应该在链上?是否存在一个同样无需信任、去中心化的执行系统?这是 DCompute 系统能够实现的。
DCompute基础设施要做到去中心化、后量子安全,也要做到无信任,不需要或者说不应该是区块链/分布式技术,但验证计算结果,正确的状态转换和最终确认是非常重要的。EVM 链的运行就是如此,在保持网络的安全性和不可篡改性的同时,去中心化的、无需信任的、安全的计算可以被移到链下。
我们在这里主要忽略的是数据可用性的问题。这篇文章并非不关注数据的可用性,因为像Celestia 和 EigenDA 这样的解决方案已经在朝这个方向发展。
1: 只将计算外包(Only Compute Outsourced)

(来源:Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
2. 将计算与数据可用性外包

(来源:Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
当我们看到 Type 1时,zk-rollups 已经在做这个,但它们要么受限于EVM,要么需要教导开发者学习全新的语言/指令集。理想的解决方案应该是高效的、有效的(成本和资源)、去中心化的、私密的和可验证的。ZK证明可以在AWS服务器上构建,但它们并不是去中心化的。像Nillion和Nexus这样的解决方案正在尝试以去中心化的方式解决通用计算的问题。但这些解决方案是无法验证的,如果没有ZK证明的话。
Type 2 将链下计算模型与保持分离的数据可用性层结合起来,但计算仍然需要在链上进行验证。
让我们来看一下今天可用的不完全可信和可能完全无信任的不同去中心化计算模型。
其他计算系统(Alternative Computation s)

以太坊外包计算生态图 (来源:IOSG Ventures)
- 安全飞地计算(Secure Enclave Computations)/可信执行环境(Trusted ution Environments)
TEE(可信执行环境)就像计算机或智能手机内部的一个特殊盒子。它有自己的锁和钥匙,只有特定的程序(称为可信应用程序)才能访问。当这些可信应用程序在TEE内部运行时,它们就受到其他程序甚至操作系统本身的保护。
这就像一个只有几个特殊朋友可以进入的秘密藏身处。TEE最常见的例子是安全隔离区,它们存在于我们使用的设备上,例如苹果的T1芯片和英特尔的SGX,用于在设备内部运行关键操作,如FaceID。
由于TEE是隔离的系统,认证过程无法被破坏,因为认证中存在信任假设。可以将其想象为存在一个安全门,你相信它是安全的,因为Intel或Apple建造了它,但世界上有足够多的安全破坏者(包括黑客和其他计算机),可以破坏这扇安全门。TEE不是“后量子安全”的,这意味着拥有无限资源的量子计算机可以破解TEE的安全性。随着计算机迅速变得更加强大,我们必须在构建长期计算系统和密码学方案时牢记后量子安全性。
- 安全多方计算(SMPC)
SMPC(安全多方计算)也是区块链技术从业熟知的一种计算方案,在SMPC网络中大致的工作流程会有如下3部分组成:
- 步骤1:将计算的输入转换为份额(shares),并分布在SMPC节点之间。
- 步骤2:进行实际的计算,通常涉及SMPC节点之间的消息交换。在此步骤结束时,每个节点将拥有计算输出值的一个份额。
- 步骤3:将结果份额发送到一个或多个结果节点,这些节点运行LSS(秘密分享恢复算法)以重构输出结果。
想象一个汽车生产线,汽车的构建和制造组件(发动机、车门、后视镜)被外包给原始设备制造商(OEM)(工作节点),然后有一个装配线,将所有组件组装在一起制造汽车(结果节点)。
秘密分享(Secret sharing)对于保护隐私的去中心化计算模型非常重要。这可以防止单个参与方获得完整的"秘密"(在这种情况下是输入),并恶意产生错误的输出。SMPC可能是最容易和最安全的去中心化系统之一。虽然目前不存在一个完全去中心化的模型,但从逻辑上讲这是有可能的。
像Sharemind这样的MPC提供商为计算提供MPC基础设施,但提供商仍然是集中的。如何确保隐私,如何确保网络(或Sharemind)没有恶意行为?这就是zk证明和zk可验证计算的由来。
- Nil Message Compute(NMC)
NMC是由Nillion团队开发的一种新的分布式计算方法。它是MPC的升级版,其中节点无需通过通过结果交互来进行通信。为此,他们使用了一种称为一次掩码(One-Time Masking)的密码原语,利用一系列称为遮蔽因子(blinding factors)的随机数来掩盖一个Secret,类似于一次性填充。OTM旨在以高效的方式提供正确性,这意味着NMC节点不需要交换任何消息来执行计算。这意味着NMC不会有SMPC的可扩展性问题。
- 零知识可验证计算
ZK可验证计算(ZK Verifiable Computation)是对一组输入和一个函数生成零知识证明,并证明任何系统执行的计算都会是正确执行的。尽管ZK验证计算是新生事物,但它已经是以太坊网络扩展路线图中一个非常关键的部分,
ZK证明有各种各样的实现形式(如下图所示,根据论文“Off-Chaining_Models”中总结):
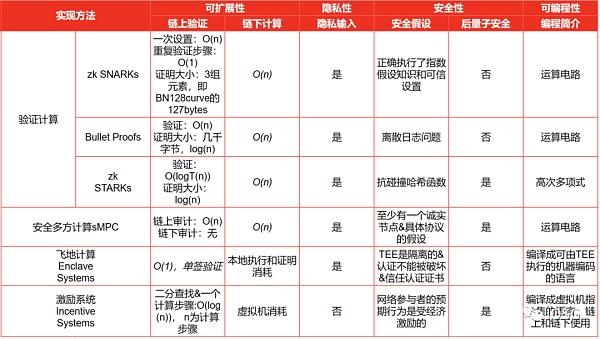
(来源:IOSG Ventures, Off-chaining Models and Approaches to Off-chain Computations, Jacob Eberhardt & Jonathan Heiss)
上面我们对zk证明的实现方式有了基本的了解,那么使用ZK证明验证计算需要什么条件呢?
- 首先,我们需要选择一个证明原语,理想的证明原语生成证明的成本低,对内存的要求不高,并且要易于验证
- 其次,选择一种zk电路,设计用于通过计算生成上述原语的证明
- 最后,在某个计算系统/网络中通过提供的输入对给定的函数进行计算并给出输出。
开发者的难题 - 证明效率困境
另外一个不得不说的事情就是构建电路的门槛还是很高,让开发者学习Solidity已经不是一件容易的事情,现在要求开发者学习Circom等来构建电路,或者学习一门特定的编程语言(如Cairo)来构建zk-apps,这似乎是一个遥不可及的事情。

(来源:

(来源:
如上面的统计数据显示,将Web3的环境改造得更适于开发,似乎比将开发人员引入新的Web3开发环境更具可持续性。
如果ZK是Web3的未来,Web3应用程序需要使用现有的开发人员技能来构建,那么ZK电路就需要这样设计:支持由Java或Rust等语言编写的算法执行的计算生成证明。
这样的解决方案确实存在,笔者想到的是两个团队:RiscZero和Lurk Labs。两个团队都有一个非常相似的愿景,即他们允许开发人员无需经历陡峭的学习曲线即可构建zk-app。
Lurk Labs还处于早期阶段,但该团队已经在这个项目上工作了很长时间。他们专注于通过通用电路生成Nova证明(Nova Proof)。Nova证明是由卡耐基梅隆大学的Abhiram Kothapalli和微软研究院的Srinath Setty以及纽约大学的 Ioanna Tziallae 提出的。与其他SNARK系统相比,Nova证明在进行增量可验证计算(IVC)方面具有特殊优势。增量可验证计算(IVC)是计算机科学和密码学中的一个概念,旨在实现计算的验证,而无需从头开始重新计算整个计算。当计算时间长且复杂时,需要针对IVC对证明进行优化。

(来源:IOSG Ventures)
Nova证明不像其他证明系统那样“开箱即用”, Nova 只是一个折叠技巧,开发者仍需要一个证明系统来生成证明。这就是为什么Lurk Labs构建了Lurk Lang,这是一个LISP实现。由于LISP是一种较低级的语言,它使得在通用电路上生成证明很容易,并且也很容易转译成Java,这将帮助Lurk Labs获得1740万Java开发者的支持。也支持其他通用语言,如Python的转译。
总而言之,Nova证明似乎是一个伟大的原始证明系统。虽然它们的缺点是证明的大小随着计算的大小线性增加,但另一方面,Nova证明有进一步的压缩空间。
STARK证明的大小不会随着计算量的增加而增加,因此它更适合验证非常大的计算。为了进一步改善开发人员的体验,他们还发布了Bonsai 网络,这是一个分布式计算网络,由RiscZero生成的证明进行验证。这是一个简单的示意图,代表RiscZero的Bonsai 网络的工作原理。

(来源:
Bonsai网络设计的美妙之处在于计算可以初始化,验证,输出全部做到链上。所有这些听起来都像是乌托邦,但STARK证明也带来了问题——验证成本太高。
Nova证明似乎非常适合重复计算(它的折叠方案经济高效)和小型计算,这可能使Lurk成为ML推理验证的一个很好的解决方案。
谁是赢家?


(来源:IOSG Ventures)
一些zk-SNARK系统在初始设置阶段需要一个可信的设置过程,生成一组初始参数。这里的信任假设是,可信的设置是诚实执行的,没有任何恶意行为或篡改。如果受到攻击,可能会导致创建无效的证明。
STARK证明假设低阶测试的安全性,用于验证多项式的低阶性质。它们还假设哈希函数表现得像随机预言机一样。
两个系统的正确实施也是一个安全假设。
SMPC网络依赖于以下几点:
- SMPC参与者可以包括“诚实但好奇“的参与者,他们可以通过与其他节点通信来尝试访问任何底层信息。
- SMPC网络的安全性依赖于参与者正确执行协议并不故意引入错误或恶意行为的假设。
- 某些SMPC协议可能需要一个可信的设置阶段来生成加密参数或初始值。这里的信任假设是可信设置被诚实执行。
- 与SMPC网络相同,安全假设保持不变,但由于OTM(Off-The-Grid Multi-party Computation)的存在,不存在“诚实但好奇“的参与者。
OTM是一种多方计算协议,旨在保护参与者的隐私。它通过使参与者在计算中不公开其输入数据来实现隐私保护。因此,“诚实但好奇“的参与者不会存在,因为他们无法通过与其他节点通信来试图访问底层信息。
有明确的赢家吗? 我们不知道。但每种方法都有自己的优点。虽然NMC看起来像是SMPC的明显升级,但该网络还没有上线,也没有经过实战测试。
使用ZK可验证计算的好处是它是安全和隐私保护的,但它没有内置的秘密共享功能。证明生成和验证之间的不对称使它成为可验证外包计算的理想模型。如果系统使用纯粹的zk验证计算,则计算机(或单个节点)必须非常强大才能执行大量计算。为了在保护隐私的同时启用负载共享和平衡,必须有秘密共享。在这种情况下,像SMPC或NMC这样的系统可以与像Lurk或RiscZero这样的zk生成器相结合,以创建强大的分布式可验证外包计算基础设施。
当今的MPC/SMPC网络是中心化的,这一点变得尤为重要。目前最大的MPC提供商是Sharemind,它上面的ZK验证层可以证明是有用的。去中心化MPC网络的经济模型尚未跑通。理论上,NMC模式是MPC系统的升级,但我们还没有看到其成功。
在ZK证明方案的竞赛中,可能不会出现赢家通吃的情况。每种证明方法都针对特定类型的计算进行了优化,并且没有一个适合所有类型的模型。计算任务的类型有很多种,也取决于开发人员在每个证明系统上做出的权衡。笔者认为基于STARK的系统和基于SNARK的系统以及它们未来的优化在ZK的未来都有一席之地。
Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.