人工知能の急速な発展は複雑なインフラストラクチャに基づいています。AIテクノロジースタックはハードウェアとソフトウェアで構成された階層構造であり、現在のAI革命の支柱です。ここでは、テクノロジースタックの主要なレイヤーについて詳しく分析し、各レイヤーがAIの開発と実装にどのように貢献しているかを説明します。最後に、これらの基本的な知識を理解することの重要性、特に暗号化資産とAIの交差領域の機会を評価する際に、DePIN(分散化物理インフラストラクチャ)プロジェクト、例えばGPUネットワークなどについて考察します。### 1.ハードウェア層:シリコンベース最下層にはハードウェアがあり、人工知能に物理計算能力を提供します。CPU(中央処理装置):計算の基本的な処理装置です。それらは順次タスクの処理に秀でており、一般的な計算には非常に重要です。データの前処理、小規模なAIタスク、および他のコンポーネントの調整などに使用されます。GPU(グラフィックス処理ユニット):もともとグラフィックスレンダリング用に設計されたが、大量の単純な計算を同時に実行できるため、人工知能の重要な構成要素となった。この並列処理能力により、GPUはデプス学習モデルのトレーニングに非常に適しており、GPUの開発がなければ、現代のGPTモデルを実現することはできませんでした。AIアクセラレータ:人工知能のワークロードに特化したチップで、一般的な人工知能操作に最適化され、トレーニングおよび推論タスクに高性能かつ高効率なソリューションを提供します。FPGA(フィールドプログラマブルゲートアレイ):その再プログラム可能な特性により、柔軟性を提供します。特に、低レイテンシーの推論シーンで特定の人工知能タスクに最適化することができます。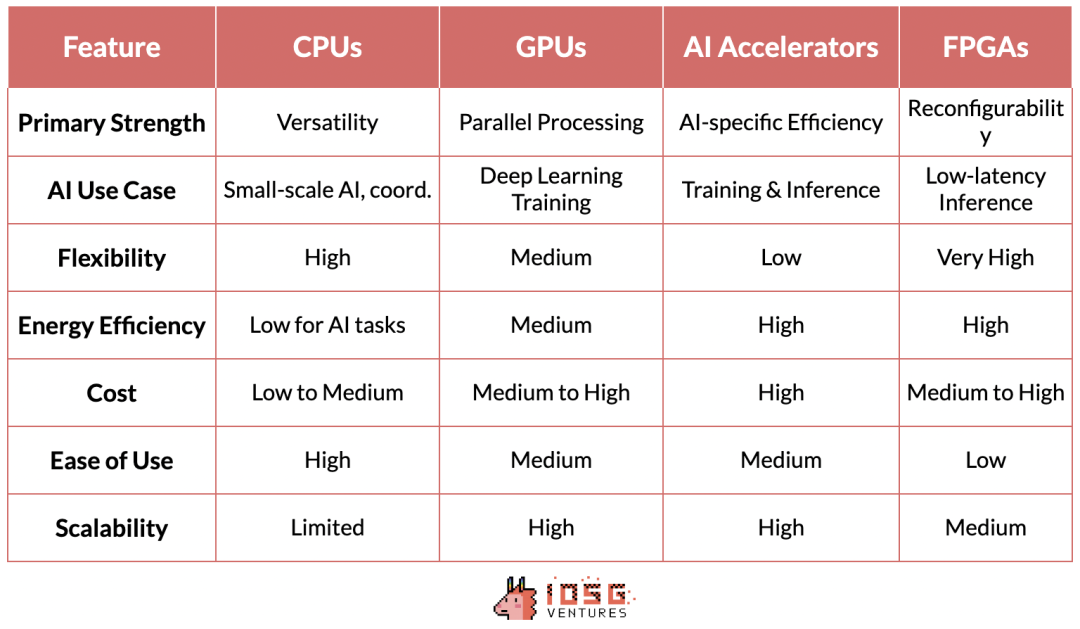### 2. 底层软件:ミドルウェアAI テクノロジ スタックのこのレイヤーは、高レベルの AI フレームワークと基盤となるハードウェアの間の架け橋となるため、非常に重要です。 CUDA、ROCm、OneAPI、SNPEなどのテクノロジーは、高レベルのフレームワークと特定のハードウェアアーキテクチャ間のリンクを強化して、パフォーマンスを最適化します。NVIDIAのプロプライエタリソフトウェアレイヤーであるCUDAは、同社がAIハードウェア市場で台頭するための基盤です。NVIDIAのリーダーシップは、ハードウェアの優位性だけでなく、ソフトウェアとエコシステムの強力なネットワーク効果を体現しています。CUDAが大きな影響力を持つ理由は、AI技術スタックに深く組み込まれ、この分野で事実上の標準となった最適化ライブラリを提供しているからです。このソフトウェアエコシステムは、CUDAに精通したAI研究者や開発者が学術界や産業界に広がるトレーニングプロセスで使用することで、強力なネットワーク効果を構築しています。この好循環により、CUDAベースのツールとライブラリのエコシステムがAIプロフェッショナルにとってますます不可欠になり、NVIDIAの市場リーダーシップを強化しています。このソフトウェアとハードウェアの共存は、NVIDIAのAIコンピューティングの先端地位を固めるだけでなく、会社に著しい価格設定能力を与え、一般的なハードウェア市場ではめったに見られないものです。CUDAの支配的地位と競争相手の比較的無名の存在は、複数の要因に起因しており、重要な進入障壁を作り出しています。NVIDIAのGPUアクセラレーション計算分野での先行優位性が、競争相手が足元をすくわれる前に、CUDAが強力なエコシステムを確立することを可能にしました。AMDやIntelなどの競合他社は、優れたハードウェアを持っている一方で、ソフトウェア層に必要なライブラリやツールが不足しており、既存の技術スタックとシームレスに統合できません。これが、NVIDIA/CUDAと他の競合他社の間に大きな差がある理由です。### 3. コンパイラ:トランスレーターTVM(テンソル仮想マシン)、MLIR(多層中間表現)およびPlaidMLは、さまざまなハードウェアアーキテクチャに対応したAIワークロードを最適化するためのさまざまな解決策を提供しています。TVMは、ワシントン大学の研究に基づいており、高性能なGPUからリソース制約のあるエッジデバイスまで、デプス学習モデルを最適化することで迅速にフォローを得ることができます。その利点はエンドツーエンドの最適化プロセスであり、特に推論シナリオで効果的です。それはベンダーやハードウェアの差異を完全に抽象化し、NVIDIAデバイスからAMD、Intelなどのさまざまなハードウェア上で推論ワークロードをシームレスに実行できるようにします。しかし、推論以外では、状況はより複雑になります。 コンピューティングの代替としてAIでトレーニングされたハードウェアの最終的な目標は、未解決のままです。 ただし、この点に関して言及する価値のあるいくつかのイニシアチブがあります。MLIRは、Googleのプロジェクトであり、より基本的な手法を採用しています。複数の抽象レベルについて統一された中間表現を提供することで、推論およびトレーニングのユースケースに対応するために、コンパイラの基盤を簡素化することを目的としています。PlaidMLは、現在Intelによってリードされ、競争の中でのダークホースと位置付けています。それは伝統的なAIアクセラレータ以外の複数のハードウェアアーキテクチャに焦点を当て、AIワークロードがさまざまな計算プラットフォームでシームレスに実行される未来を展望しています。これらのコンパイラのいずれかがテックスタックにうまく統合され、モデルのパフォーマンスに影響を与えず、開発者が追加の変更を行う必要もない場合、それはCUDAのモートンの脅威となる可能性があります。しかし、現在のところ、MLIRとPlaidMLはまだ十分に成熟しておらず、人工知能のテックスタックにうまく統合されていませんので、それらは現時点ではCUDAのリーダーシップに明確な脅威を与えるものではありません。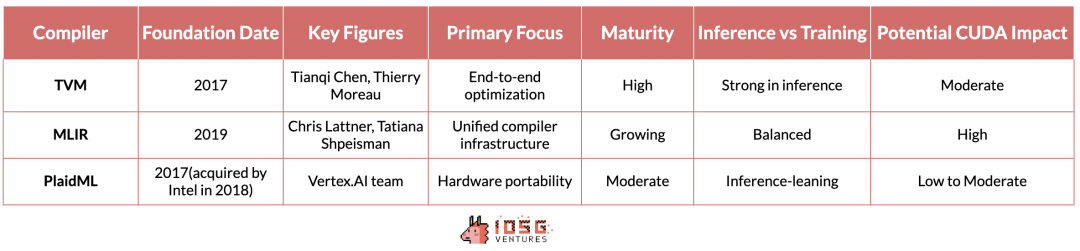### 4. 分散コンピューティング:コーディネーターRayとHorovodは、AI領域の分散コンピューティングの2つの異なる方法を表しており、それぞれが大規模なAIアプリケーションのスケーラブルな処理の重要な要件を解決しています。UC BerkeleyのRISELabによって開発されたRayは、汎用の分散コンピューティングフレームワークです。柔軟性に優れており、機械学習以外のさまざまなタイプのワークロードを割り当てることができます。Rayのアクターベースのモデルは、Pythonコードの並列化プロセスを大幅に簡素化し、特に強化学習や他の複雑で多様なワークフローが必要な人工知能タスクに適しています。Horovodは、元々Uberによって設計され、デプス学習の分散実装に焦点を当てています。複数のGPUおよびサーバーノードでのデプス学習トレーニングプロセスの拡張に、簡潔で効率的な解決策を提供しています。Horovodの特筆すべき点は、ユーザーフレンドリーな点とニューラルネットワークのデータ並列トレーニングの最適化にあり、これにより、TensorFlow、PyTorchなどの主要なデプス学習フレームワークと完璧に統合され、開発者は既存のトレーニングコードを容易に拡張することができます。大幅なコード変更が不要となります。### 5. 閉会挨拶:暗号通貨の視点から分散型コンピューティングシステムを構築するDePinプロジェクトにとって、既存のAIスタックとの統合は非常に重要です。この統合により、現在のAIワークフローとツールとの互換性が保証され、採用のハードルがドロップされます。暗号資産の領域では、現在のGPUネットワークは本質的に分散化されたGPUレンタルプラットフォームであり、これはより複雑な分散型AIインフラへの初歩的なステップを示しています。これらのプラットフォームは、分散型クラウドではなく、Airbnbのようなマーケットのような存在です。これらのプラットフォームは特定のアプリケーションには有用ですが、本格的な分散型トレーニングをサポートするにはまだ十分ではありません。これは大規模なAI開発を推進するための重要な要件です。現在の分散コンピューティングスタンダードであるRayやHorovodのようなものは、グローバルな分散ネットワークを対象としていないため、実際に機能する分散ネットワークを構築するためには、別のフレームワークをこのレベルで開発する必要があります。一部の懐疑論者は、Transformerモデルが学習中に密な通信とグローバルな機能の最適化が必要であり、これらは分散トレーニング手法と互換性がないと考えています。一方で、楽観主義者は、グローバルに分散したハードウェアとうまく連携する新しい分散コンピューティングフレームワークを提案しようとしています。Yottaは、この問題に取り組もうとしているスタートアップ企業の1つです。NeuroMeshはさらに進化しました。それは機械学習プロセスを特に革新的な方法で再設計しています。グローバルな損失関数の最適解を直接探すのではなく、局所的な誤差の最小化収束を予測エンコーディングネットワーク(PCN)を使用して見つけることで、NeuroMeshは分散型AIトレーニングの根本的なボトルネックを解決しています。この方法により、前例のない並列化が実現され、消費者向けのGPUハードウェア(RTX 4090など)でのモデルトレーニングが可能になり、AIトレーニングの民主化が実現されました。具体的には、4090 GPUの計算能力はH100に似ていますが、帯域幅の不足のため、モデルトレーニングのプロセスで十分に活用されていませんでした。PCNが帯域幅の重要性を低下させたため、これらの低コストなGPUを活用することが可能になり、著しいコスト削減と効率向上がもたらされる可能性があります。GenSyn、もう一つの野心的な暗号化AIスタートアップ企業で、罠コンパイラを構築することを目指しています。Gensynのコンパイラは、あらゆる種類のコンピューティングハードウェアをシームレスにAIワークロードに使用することができます。例えば、TVMが推論に対して果たす役割のように、GenSynはモデルトレーニングのための類似のツールを構築しようとしています。成功すれば、それは分散型AIコンピューティングネットワークの能力を大幅に拡張することができ、さまざまなハードウェアを効率的に活用してより複雑で多様なAIタスクを処理することができます。この野心的なビジョンは、多様なハードウェアアーキテクチャの最適化の複雑さと高い技術リスクにより挑戦的なものですが、異種システムのパフォーマンスの維持などの障壁を乗り越えることができれば、この技術はCUDAとNVIDIAの堀を弱める可能性があります。推論について:Hyperbolicのアプローチは、検証可能な推論と異種計算リソースの分散化ネットワークを組み合わせることで、比較的実用的な戦略を実現しています。TVMなどのコンパイラ標準を活用することで、Hyperbolicは幅広いハードウェア構成を利用しながら、パフォーマンスと信頼性を確保することができます。NVIDIAからAMD、Intelなどのさまざまなベンダーのチップ(コンシューマーレベルのハードウェアやハイパフォーマンスハードウェアを含む)を集約することができます。これらの暗号化AI交差領域の発展は、AI計算がより分散化、効率的、アクセス可能になる未来を示唆しています。これらのプロジェクトの成功は、技術的優位性だけでなく、既存のAIワークフローにシームレスに統合される能力、およびAIプラクティショナーや企業の実際の関心事を解決する能力にも依存します。

IOSG:シリコンからインテリジェントへ、人工知能トレーニングと推論技術スタック
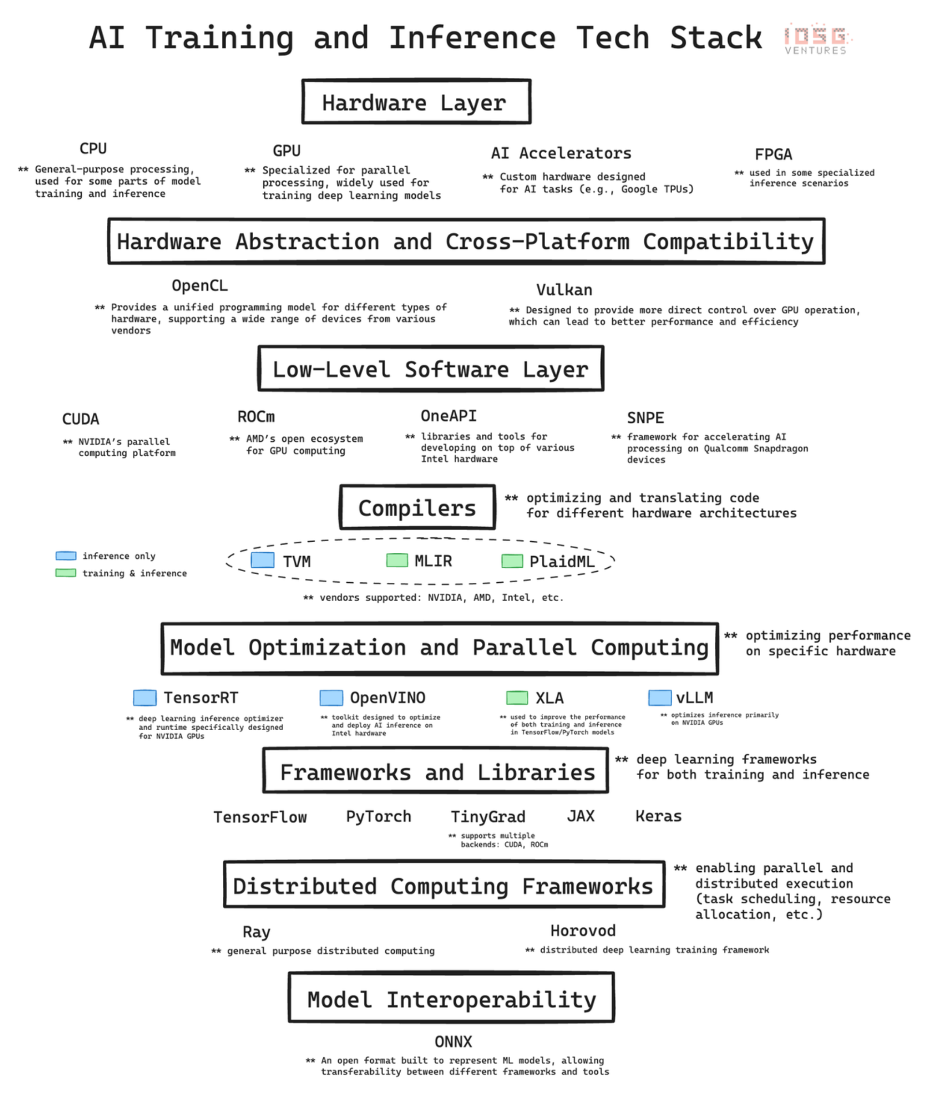
人工知能の急速な発展は複雑なインフラストラクチャに基づいています。AIテクノロジースタックはハードウェアとソフトウェアで構成された階層構造であり、現在のAI革命の支柱です。ここでは、テクノロジースタックの主要なレイヤーについて詳しく分析し、各レイヤーがAIの開発と実装にどのように貢献しているかを説明します。最後に、これらの基本的な知識を理解することの重要性、特に暗号化資産とAIの交差領域の機会を評価する際に、DePIN(分散化物理インフラストラクチャ)プロジェクト、例えばGPUネットワークなどについて考察します。
1.ハードウェア層:シリコンベース
最下層にはハードウェアがあり、人工知能に物理計算能力を提供します。
CPU(中央処理装置):計算の基本的な処理装置です。それらは順次タスクの処理に秀でており、一般的な計算には非常に重要です。データの前処理、小規模なAIタスク、および他のコンポーネントの調整などに使用されます。
GPU(グラフィックス処理ユニット):もともとグラフィックスレンダリング用に設計されたが、大量の単純な計算を同時に実行できるため、人工知能の重要な構成要素となった。この並列処理能力により、GPUはデプス学習モデルのトレーニングに非常に適しており、GPUの開発がなければ、現代のGPTモデルを実現することはできませんでした。
AIアクセラレータ:人工知能のワークロードに特化したチップで、一般的な人工知能操作に最適化され、トレーニングおよび推論タスクに高性能かつ高効率なソリューションを提供します。
FPGA(フィールドプログラマブルゲートアレイ):その再プログラム可能な特性により、柔軟性を提供します。特に、低レイテンシーの推論シーンで特定の人工知能タスクに最適化することができます。
2. 底层软件:ミドルウェア
AI テクノロジ スタックのこのレイヤーは、高レベルの AI フレームワークと基盤となるハードウェアの間の架け橋となるため、非常に重要です。 CUDA、ROCm、OneAPI、SNPEなどのテクノロジーは、高レベルのフレームワークと特定のハードウェアアーキテクチャ間のリンクを強化して、パフォーマンスを最適化します。
NVIDIAのプロプライエタリソフトウェアレイヤーであるCUDAは、同社がAIハードウェア市場で台頭するための基盤です。NVIDIAのリーダーシップは、ハードウェアの優位性だけでなく、ソフトウェアとエコシステムの強力なネットワーク効果を体現しています。
CUDAが大きな影響力を持つ理由は、AI技術スタックに深く組み込まれ、この分野で事実上の標準となった最適化ライブラリを提供しているからです。このソフトウェアエコシステムは、CUDAに精通したAI研究者や開発者が学術界や産業界に広がるトレーニングプロセスで使用することで、強力なネットワーク効果を構築しています。
この好循環により、CUDAベースのツールとライブラリのエコシステムがAIプロフェッショナルにとってますます不可欠になり、NVIDIAの市場リーダーシップを強化しています。
このソフトウェアとハードウェアの共存は、NVIDIAのAIコンピューティングの先端地位を固めるだけでなく、会社に著しい価格設定能力を与え、一般的なハードウェア市場ではめったに見られないものです。
CUDAの支配的地位と競争相手の比較的無名の存在は、複数の要因に起因しており、重要な進入障壁を作り出しています。NVIDIAのGPUアクセラレーション計算分野での先行優位性が、競争相手が足元をすくわれる前に、CUDAが強力なエコシステムを確立することを可能にしました。AMDやIntelなどの競合他社は、優れたハードウェアを持っている一方で、ソフトウェア層に必要なライブラリやツールが不足しており、既存の技術スタックとシームレスに統合できません。これが、NVIDIA/CUDAと他の競合他社の間に大きな差がある理由です。
3. コンパイラ:トランスレーター
TVM(テンソル仮想マシン)、MLIR(多層中間表現)およびPlaidMLは、さまざまなハードウェアアーキテクチャに対応したAIワークロードを最適化するためのさまざまな解決策を提供しています。
TVMは、ワシントン大学の研究に基づいており、高性能なGPUからリソース制約のあるエッジデバイスまで、デプス学習モデルを最適化することで迅速にフォローを得ることができます。その利点はエンドツーエンドの最適化プロセスであり、特に推論シナリオで効果的です。それはベンダーやハードウェアの差異を完全に抽象化し、NVIDIAデバイスからAMD、Intelなどのさまざまなハードウェア上で推論ワークロードをシームレスに実行できるようにします。
しかし、推論以外では、状況はより複雑になります。 コンピューティングの代替としてAIでトレーニングされたハードウェアの最終的な目標は、未解決のままです。 ただし、この点に関して言及する価値のあるいくつかのイニシアチブがあります。
MLIRは、Googleのプロジェクトであり、より基本的な手法を採用しています。複数の抽象レベルについて統一された中間表現を提供することで、推論およびトレーニングのユースケースに対応するために、コンパイラの基盤を簡素化することを目的としています。
PlaidMLは、現在Intelによってリードされ、競争の中でのダークホースと位置付けています。それは伝統的なAIアクセラレータ以外の複数のハードウェアアーキテクチャに焦点を当て、AIワークロードがさまざまな計算プラットフォームでシームレスに実行される未来を展望しています。
これらのコンパイラのいずれかがテックスタックにうまく統合され、モデルのパフォーマンスに影響を与えず、開発者が追加の変更を行う必要もない場合、それはCUDAのモートンの脅威となる可能性があります。しかし、現在のところ、MLIRとPlaidMLはまだ十分に成熟しておらず、人工知能のテックスタックにうまく統合されていませんので、それらは現時点ではCUDAのリーダーシップに明確な脅威を与えるものではありません。
4. 分散コンピューティング:コーディネーター
RayとHorovodは、AI領域の分散コンピューティングの2つの異なる方法を表しており、それぞれが大規模なAIアプリケーションのスケーラブルな処理の重要な要件を解決しています。
UC BerkeleyのRISELabによって開発されたRayは、汎用の分散コンピューティングフレームワークです。柔軟性に優れており、機械学習以外のさまざまなタイプのワークロードを割り当てることができます。Rayのアクターベースのモデルは、Pythonコードの並列化プロセスを大幅に簡素化し、特に強化学習や他の複雑で多様なワークフローが必要な人工知能タスクに適しています。
Horovodは、元々Uberによって設計され、デプス学習の分散実装に焦点を当てています。複数のGPUおよびサーバーノードでのデプス学習トレーニングプロセスの拡張に、簡潔で効率的な解決策を提供しています。Horovodの特筆すべき点は、ユーザーフレンドリーな点とニューラルネットワークのデータ並列トレーニングの最適化にあり、これにより、TensorFlow、PyTorchなどの主要なデプス学習フレームワークと完璧に統合され、開発者は既存のトレーニングコードを容易に拡張することができます。大幅なコード変更が不要となります。
5. 閉会挨拶:暗号通貨の視点から
分散型コンピューティングシステムを構築するDePinプロジェクトにとって、既存のAIスタックとの統合は非常に重要です。この統合により、現在のAIワークフローとツールとの互換性が保証され、採用のハードルがドロップされます。
暗号資産の領域では、現在のGPUネットワークは本質的に分散化されたGPUレンタルプラットフォームであり、これはより複雑な分散型AIインフラへの初歩的なステップを示しています。これらのプラットフォームは、分散型クラウドではなく、Airbnbのようなマーケットのような存在です。これらのプラットフォームは特定のアプリケーションには有用ですが、本格的な分散型トレーニングをサポートするにはまだ十分ではありません。これは大規模なAI開発を推進するための重要な要件です。
現在の分散コンピューティングスタンダードであるRayやHorovodのようなものは、グローバルな分散ネットワークを対象としていないため、実際に機能する分散ネットワークを構築するためには、別のフレームワークをこのレベルで開発する必要があります。一部の懐疑論者は、Transformerモデルが学習中に密な通信とグローバルな機能の最適化が必要であり、これらは分散トレーニング手法と互換性がないと考えています。一方で、楽観主義者は、グローバルに分散したハードウェアとうまく連携する新しい分散コンピューティングフレームワークを提案しようとしています。Yottaは、この問題に取り組もうとしているスタートアップ企業の1つです。
NeuroMeshはさらに進化しました。それは機械学習プロセスを特に革新的な方法で再設計しています。グローバルな損失関数の最適解を直接探すのではなく、局所的な誤差の最小化収束を予測エンコーディングネットワーク(PCN)を使用して見つけることで、NeuroMeshは分散型AIトレーニングの根本的なボトルネックを解決しています。
この方法により、前例のない並列化が実現され、消費者向けのGPUハードウェア(RTX 4090など)でのモデルトレーニングが可能になり、AIトレーニングの民主化が実現されました。具体的には、4090 GPUの計算能力はH100に似ていますが、帯域幅の不足のため、モデルトレーニングのプロセスで十分に活用されていませんでした。PCNが帯域幅の重要性を低下させたため、これらの低コストなGPUを活用することが可能になり、著しいコスト削減と効率向上がもたらされる可能性があります。
GenSyn、もう一つの野心的な暗号化AIスタートアップ企業で、罠コンパイラを構築することを目指しています。Gensynのコンパイラは、あらゆる種類のコンピューティングハードウェアをシームレスにAIワークロードに使用することができます。例えば、TVMが推論に対して果たす役割のように、GenSynはモデルトレーニングのための類似のツールを構築しようとしています。
成功すれば、それは分散型AIコンピューティングネットワークの能力を大幅に拡張することができ、さまざまなハードウェアを効率的に活用してより複雑で多様なAIタスクを処理することができます。この野心的なビジョンは、多様なハードウェアアーキテクチャの最適化の複雑さと高い技術リスクにより挑戦的なものですが、異種システムのパフォーマンスの維持などの障壁を乗り越えることができれば、この技術はCUDAとNVIDIAの堀を弱める可能性があります。
推論について:Hyperbolicのアプローチは、検証可能な推論と異種計算リソースの分散化ネットワークを組み合わせることで、比較的実用的な戦略を実現しています。TVMなどのコンパイラ標準を活用することで、Hyperbolicは幅広いハードウェア構成を利用しながら、パフォーマンスと信頼性を確保することができます。NVIDIAからAMD、Intelなどのさまざまなベンダーのチップ(コンシューマーレベルのハードウェアやハイパフォーマンスハードウェアを含む)を集約することができます。
これらの暗号化AI交差領域の発展は、AI計算がより分散化、効率的、アクセス可能になる未来を示唆しています。これらのプロジェクトの成功は、技術的優位性だけでなく、既存のAIワークフローにシームレスに統合される能力、およびAIプラクティショナーや企業の実際の関心事を解決する能力にも依存します。