Perdagangan
Tipe perdagangan
Spot
Perdagangkan kripto dengan bebas
Alpha
Poin
Dapatkan token yang menjanjikan dalam perdagangan on-chain yang efisien
Pre-Market
Perdagangkan token baru sebelum di list secara resmi
Perdagangan Margin
Perbesar keuntungan Anda dengan leverage
Perdagangan Konversi & Blok
0 Fees
Perdagangkan dalam ukuran berapa pun tanpa biaya dan tanpa slippage
Token Leverage
Dapatkan eksposur ke posisi leverage dengan mudah
Futures
Futures
Ratusan kontrak diselesaikan dalam USDT atau BTC
Opsi
HOT
Perdagangkan Opsi Vanilla ala Eropa
Akun Terpadu
Memaksimalkan efisiensi modal Anda
Perdagangan Demo
Futures Kickoff
Bersiap untuk perdagangan futures Anda
Acara Futures
Berpartisipasi dalam acara untuk memenangkan hadiah besar
Perdagangan Demo
Gunakan dana virtual untuk merasakan perdagangan bebas risiko
Earn
Peluncuran
CandyDrop
Koleksi permen untuk mendapatkan airdrop
Launchpool
Staking cepat, dapatkan token baru yang potensial
HODLer Airdrop
Pegang GT dan dapatkan airdrop besar secara gratis
Launchpad
Jadi yang pertama untuk proyek token besar berikutnya
Web3 BountyDrop
Dapatkan airdrop Web3 besar-besaran dengan satu klik
Investasi
Simple Earn
VIP
Dapatkan bunga dengan token yang menganggur
Investasi Otomatis
Investasi otomatis secara teratur
Investasi Ganda
Beli saat harga rendah dan jual saat harga tinggi untuk mengambil keuntungan dari fluktuasi harga
Dana Quant
VIP
Tim manajemen aset teratas membantu Anda mendapatkan keuntungan tanpa kesulitan
Pinjaman Kripto
0 Fees
Menjaminkan satu kripto untuk meminjam kripto lainnya
Pusat Peminjaman
Hub Peminjaman Terpadu
Pusat Kekayaan VIP
New
Manajemen kekayaan kustom memberdayakan pertumbuhan Aset Anda
Staking
Stake kripto untuk mendapatkan penghasilan dalam produk PoS
BTC Staking
HOT
Stake BTC dan dapatkan 10% APR
ETH Staking
HOT
Stake ETH dan dapatkan 6% APR
GSUD Minting
New
Gunakan USDT/USDC untuk mint GUSD untuk imbal hasil tingkat treasury
Soft Staking
Dapatkan hadiah dengan staking fleksibel
Lainnya


- Topik TrendingLihat Lebih Banyak
9.1K Popularitas
20K Popularitas
42.6K Popularitas
37.2K Popularitas
2.2K Popularitas
- Sematkan
Mengungkap Transformer di iPhone: Berdasarkan arsitektur GPT-2, kata segmenter berisi emoji, diproduksi oleh alumni MIT
Sumber asli: Qubit
"Rahasia" Transformer Apple telah diungkap oleh para peminat.
Di tengah banyaknya model besar, meskipun Anda konservatif seperti Apple, Anda harus menyebut "Transformer" di setiap konferensi pers.
Misalnya, pada WWDC tahun ini, Apple mengumumkan bahwa versi baru iOS dan macOS akan memiliki model bahasa Transformer bawaan untuk menyediakan metode masukan dengan kemampuan prediksi teks.
Seorang pria bernama Jack Cook membalikkan macOS Sonoma beta dan menemukan banyak informasi baru:
Mari kita lihat lebih detailnya.
Berdasarkan arsitektur GPT-2
Pertama, mari kita tinjau fungsi apa saja yang dapat diterapkan oleh model bahasa berbasis Transformer Apple di iPhone, MacBook, dan perangkat lainnya.
Terutama tercermin dalam metode input. Metode masukan Apple sendiri, yang didukung oleh model bahasa, dapat mencapai fungsi prediksi kata dan koreksi kesalahan.
** **### △Sumber: postingan blog Jack Cook
**### △Sumber: postingan blog Jack Cook
Model ini terkadang memprediksi beberapa kata yang akan datang, namun hal ini terbatas pada situasi ketika semantik kalimatnya sangat jelas, mirip dengan fungsi pelengkapan otomatis di Gmail.
** **### △Sumber: postingan blog Jack Cook
**### △Sumber: postingan blog Jack Cook
Jadi di mana tepatnya model ini dipasang? Setelah menggali lebih dalam, Saudara Cook memutuskan:
Karena:
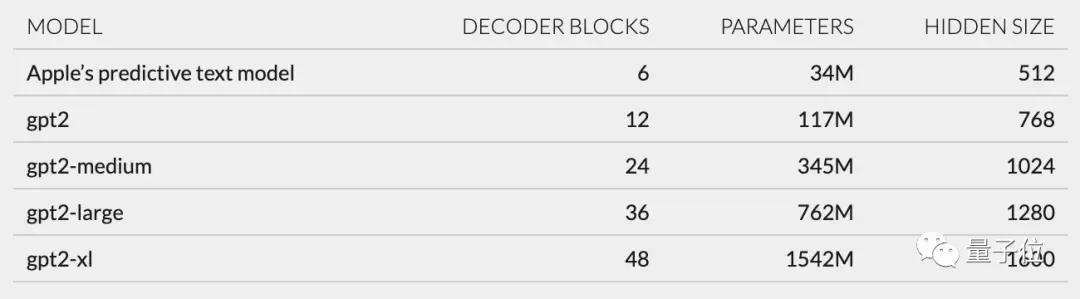
Selain itu, berdasarkan struktur jaringan yang dijelaskan di unilm_joint_cpu, saya berspekulasi bahwa model Apple didasarkan pada arsitektur GPT-2:
Ini terutama mencakup penyematan token, pengkodean posisi, blok decoder dan lapisan keluaran. Setiap blok decoder memiliki kata-kata seperti gpt2_transformer_layer_3d.
** **### △Sumber: postingan blog Jack Cook
**### △Sumber: postingan blog Jack Cook
Berdasarkan ukuran tiap lapisan, saya juga berspekulasi bahwa model Apple memiliki sekitar 34 juta parameter dan ukuran lapisan tersembunyi adalah 512. Artinya, lebih kecil dari versi terkecil GPT-2.
Saya yakin hal ini terutama karena Apple menginginkan model yang mengonsumsi lebih sedikit daya namun dapat berjalan dengan cepat dan sering.
Pernyataan resmi Apple di WWDC adalah "setiap kali tombol diklik, iPhone akan menjalankan model tersebut satu kali."
Namun hal ini juga berarti bahwa model prediksi teks ini kurang baik dalam melanjutkan kalimat atau paragraf secara lengkap.
** **### △Sumber: postingan blog Jack Cook
**### △Sumber: postingan blog Jack Cook
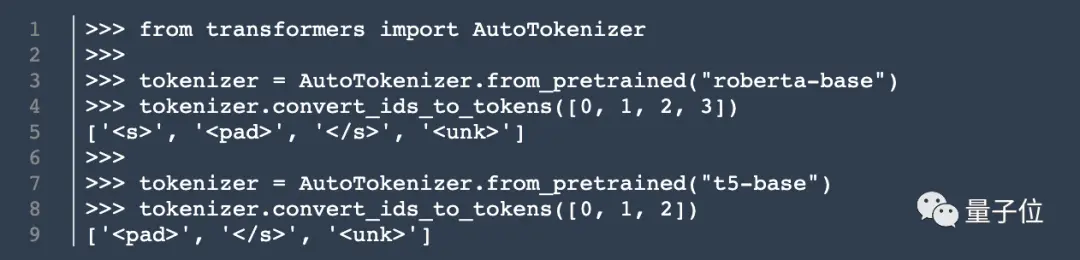
Selain arsitektur model, Cook juga menggali informasi mengenai tokenizer.
Dia menemukan satu set 15.000 token di unilm.bundle/sp.dat. Perlu dicatat bahwa itu berisi 100 emoji.
Masak mengungkap Juru Masak
Meski si juru masak ini bukan seorang juru masak, namun postingan blog saya tetap menarik banyak perhatian setelah dipublikasikan.
Sebelumnya, beliau magang di NVIDIA dengan fokus pada penelitian model bahasa seperti BERT. Ia juga merupakan insinyur penelitian dan pengembangan senior untuk pemrosesan bahasa alami di The New York Times.
Jadi, apakah wahyu tersebut juga memicu beberapa pemikiran dalam diri Anda? Selamat berbagi pandangan Anda di area komentar~
Tautan asli: