Acheter Cryptos
Payer en
USD
Achat rapide
HOT
Achetez et vendez des cryptomonnaies via Apple Pay, cartes bancaires, Google Pay, virements bancaires et d'autres méthodes de paiement.
P2P
0 Fees
Zéro frais, +400 options de paiement et une expérience ultra fluide pour acheter et vendre vos cryptos
Gate Card
Carte de paiement crypto, permettant d'effectuer des transactions mondiales en toute transparence.
Trader
Type de trading
Spot
Échangez des cryptos librement
Alpha
Points
Obtenez des actifs prometteurs dans le cadre d'un trading on-chain rationalisé
Pre-Market
Trade de nouveaux jetons avant qu'ils ne soient officiellement listés
Marge
Augmentez vos bénéfices grâce à l'effet de levier
Conversion & Trading en blocs
0 Fees
Tradez n’importe quel volume sans frais ni slippage
Tokens à effet de levier
Soyez facilement exposé à des positions à effet de levier
Futures
Futures
Des centaines de contrats réglés en USDT ou en BTC
Options
HOT
Tradez des options classiques de style européen
Compte unifié
Maximiser l'efficacité de votre capital
Demo Trading
Futures Kickoff
Préparez-vous à trader des contrats futurs
Événements futures
Participez à des événements pour gagner de généreuses récompenses
Demo Trading
Utiliser des fonds virtuels pour faire l'expérience du trading sans risque
Earn
Lancer
CandyDrop
Collecte des candies pour obtenir des airdrops
Launchpool
Staking rapide, Gagnez de potentiels nouveaux jetons
HODLer Airdrop
Conservez des GT et recevez d'énormes airdrops gratuitement
Launchpad
Soyez les premiers à participer au prochain grand projet de jetons
Web3 BountyDrop
Obtenez des airdrops Web3 massifs en un seul clic
Investissement
Simple Earn
VIP
Gagner des intérêts avec des jetons inutilisés
Investissements Automatique
Auto-invest régulier
Double investissement
Acheter à bas prix et vendre à prix élevé pour tirer profit des fluctuations de prix
Fonds Quant
VIP
Une équipe de gestion d'actifs de premier plan vous aide à réaliser des bénéfices en toute simplicité
Prêt Crypto
0 Fees
Mettre en gage un crypto pour en emprunter une autre
Centre de prêts
Centre de prêts intégré
Gestion de patrimoine VIP
New
La gestion qui fait grandir votre richesse
Staking
Stakez des cryptos pour gagner avec les produits PoS.
BTC Staking
HOT
Stakez vos BTC et gagnez 10 % d’APR
ETH Staking
HOT
Stakez vos ETH et gagnez 6 % d’APR
GUSD Minting
New
Utilisez USDT/USDC pour minter du GUSD et obtenir des rendements comparables à ceux des bons du Trésor.
Staking souple
Gagnez des récompenses grâce au staking flexible
Plus


- Sujets populairesAfficher plus
12.1K Popularité
22K Popularité
44.6K Popularité
37.3K Popularité
2.3K Popularité
- Épingler
Révéler le Transformer dans l'iPhone : basé sur l'architecture GPT-2, le segmenteur de mots contient des emoji, produits par des anciens élèves du MIT
Source originale : Qubits
Le "secret" du Transformer d'Apple a été révélé par des passionnés.
Dans la vague des grands modèles, même si l'on est aussi conservateur qu'Apple, il faut mentionner « Transformer » à chaque conférence de presse.
Par exemple, lors de la WWDC de cette année, Apple a annoncé que les nouvelles versions d'iOS et de macOS auront des modèles de langage Transformer intégrés pour fournir des méthodes de saisie avec des capacités de prédiction de texte.
Un gars nommé Jack Cook a bouleversé la version bêta de macOS Sonoma et a découvert de nombreuses nouvelles informations :
Jetons un coup d'oeil à plus de détails.
Basé sur l'architecture GPT-2
Tout d’abord, examinons les fonctions que le modèle de langage basé sur Transformer d’Apple peut implémenter sur iPhone, MacBook et autres appareils.
Cela se reflète principalement dans la méthode de saisie. La propre méthode de saisie d'Apple, prise en charge par le modèle de langage, peut réaliser des fonctions de prédiction de mots et de correction d'erreurs.
** **### △Source : article de blog de Jack Cook
**### △Source : article de blog de Jack Cook
Le modèle prédit parfois plusieurs mots à venir, mais cela est limité aux situations où la sémantique de la phrase est très évidente, similaire à la fonction de saisie semi-automatique de Gmail.
** **### △Source : article de blog de Jack Cook
**### △Source : article de blog de Jack Cook
Alors, où exactement ce modèle est-il installé ? Après quelques recherches approfondies, frère Cook a déterminé :
Parce que:
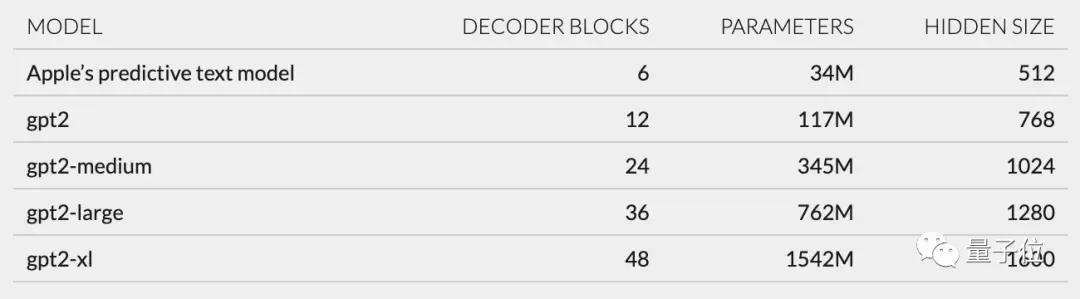
De plus, sur la base de la structure du réseau décrite dans unilm_joint_cpu, j'ai supposé que le modèle Apple est basé sur l'architecture GPT-2 :
Il comprend principalement l'intégration de jetons, le codage de position, le bloc décodeur et la couche de sortie. Chaque bloc décodeur contient des mots tels que gpt2_transformer_layer_3d.
** **### △Source : article de blog de Jack Cook
**### △Source : article de blog de Jack Cook
Sur la base de la taille de chaque couche, j'ai également supposé que le modèle Apple comporte environ 34 millions de paramètres et que la taille de la couche cachée est de 512. Autrement dit, il est plus petit que la plus petite version de GPT-2.
Je pense que c'est principalement parce qu'Apple souhaite un modèle qui consomme moins d'énergie mais qui puisse fonctionner rapidement et fréquemment.
La déclaration officielle d'Apple à la WWDC est que "chaque fois que vous cliquez sur une touche, l'iPhone exécutera le modèle une fois".
Cependant, cela signifie également que ce modèle de prédiction de texte n’est pas très efficace pour poursuivre complètement des phrases ou des paragraphes.
** **### △Source : article de blog de Jack Cook
**### △Source : article de blog de Jack Cook
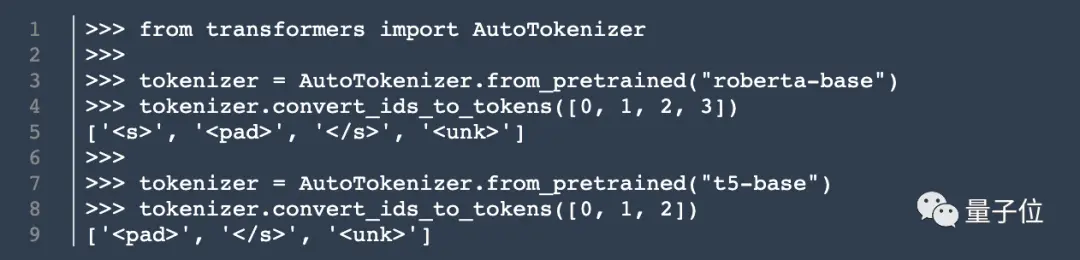
En plus de l'architecture du modèle, Cook a également découvert des informations sur le tokenizer.
Il a trouvé un ensemble de 15 000 jetons dans unilm.bundle/sp.dat. Il convient de noter qu'il contient 100 emoji.
Cook révèle Cook
Bien que ce cuisinier ne soit pas un cuisinier, mon article de blog a quand même attiré beaucoup d'attention dès sa publication.
Auparavant, il a effectué un stage chez NVIDIA, se concentrant sur la recherche de modèles de langage tels que BERT. Il est également ingénieur principal en recherche et développement pour le traitement du langage naturel au New York Times.
Alors, sa révélation a-t-elle également déclenché des réflexions dans votre esprit ? Bienvenue pour partager votre point de vue dans la zone de commentaires ~
Lien d'origine :