En resumen
- Un desarrollador descubrió que obligar a Claude a hablar como un hombre de las cavernas reduce drásticamente los tokens de salida y, por lo tanto, los costos, hasta en un 75%.
- Internet lo convirtió de inmediato en una habilidad de GitHub.
- Con Anthropic cobrando tan alto por tokens de salida, el modo gruñón deja de ser un chiste y pasa a ser una estrategia de presupuesto.
En algún punto entre la ingeniería de prompts y el performance artístico, un desarrollador publicó en Reddit un descubrimiento que hizo reír a la comunidad de la IA antes de que prestara atención: enseñarle a Claude a comunicarse como un humano prehistórico y ver cómo se reduce la factura de tokens hasta en un 75%.
La publicación llegó a r/ClaudeAI la semana pasada y desde entonces acumula más de 400 comentarios y 10K votos, una combinación poco común de perspicacia técnica genuina y comedia absurda que Internet tiende a premiar.

El mecanismo es simple. En lugar de dejar que Claude se “caliente” con cortesías, narra cada paso que da y cierra con una oferta para ayudar más; el desarrollador constriñe el modelo a frases cortas y despojadas. Herramienta primero, resultado primero, sin explicación. Una tarea normal de búsqueda web que normalmente se ejecutaría con unos 180 tokens de salida bajó a ~45. El autor original afirma una reducción de hasta 75% en la salida, lograda haciendo que el modelo suene como si acabara de descubrir el fuego.
En términos de cavernícolas, como dijo un redditor: "¿Por qué perder tiempo diciendo muchas palabras cuando pocas palabras hacen el truco?”
Lo que esta técnica no toca es el contexto de entrada: todo el historial de la conversación, los archivos adjuntos y las instrucciones del sistema que el modelo relee en cada turno. Esa entrada normalmente supera a la salida, especialmente en sesiones de codificación más largas. En sesiones del mundo real que cuentan toda esta entrada, la reducción por ahorros ronda el 25%, no el 75%. Aun así es significativo, solo que no es el número del titular.
También es una buena idea proporcionar al modelo instrucciones normales. No le des el discurso del “caveman”, porque podría desbocarse hacia una situación de “basura entra, basura sale”.
También está la cuestión de la degradación de la inteligencia. Un puñado de investigadores en el hilo argumentó que obligar a una IA a habitar una personalidad menos sofisticada podría perjudicar activamente la calidad de su razonamiento: que las restricciones verbales podrían filtrarse hacia lo cognitivo. La preocupación no se ha resuelto definitivamente, pero vale la pena tenerla en cuenta al evaluar los resultados.
Habilidad buena, habilidad se vuelve viral
A pesar de las advertencias, la técnica encontró una segunda vida en GitHub casi de inmediato.
El desarrollador Shawnchee empaquetó las reglas en una habilidad independiente compatible con caveman-skill para Claude Code, Cursor, Windsurf, Copilot y más de 40 otros agentes. La habilidad destila el enfoque en 10 reglas: sin frases de relleno, ejecutar antes de explicar, sin metacomentarios, sin prólogo, sin epílogo, sin anuncios de herramientas, explicar solo cuando sea necesario, dejar que el código hable por sí mismo y tratar los errores como cosas que hay que corregir en lugar de narrarlos.
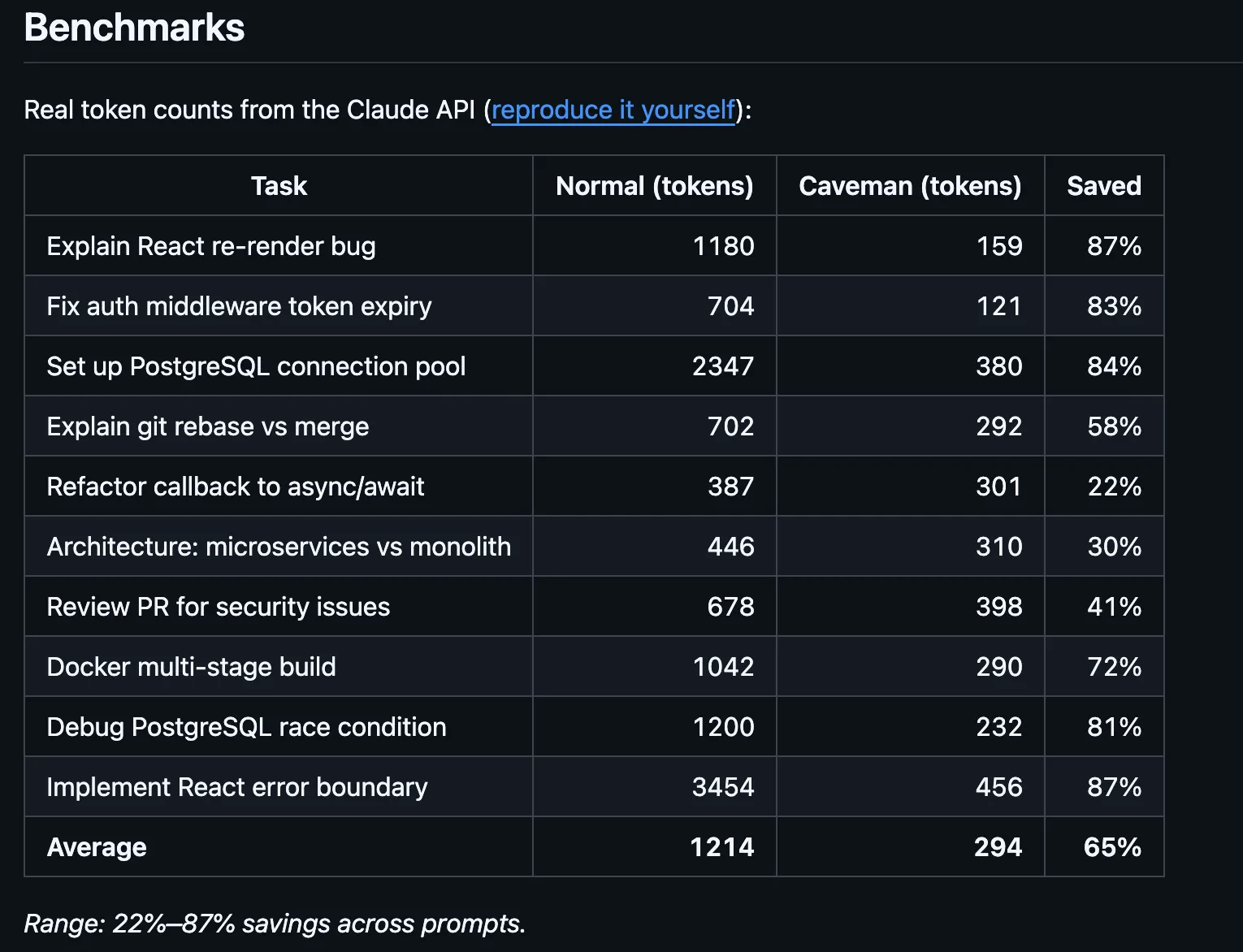
Los benchmarks del repositorio, verificados con tiktoken, muestran reducciones de tokens de salida de 68% en tareas de búsqueda web, 50% en ediciones de código y 72% en intercambios de preguntas y respuestas, para una reducción promedio de salida de 61% en cuatro tareas estándar.
Un repositorio paralelo del desarrollador Julius Brussee adoptó un enfoque ligeramente distinto, enmarcando la misma idea como un archivo SKILL.md con 562 estrellas en GitHub. La especificación: responde como un caveman inteligente, recorta artículos, relleno y cortesías, mantén toda la sustancia técnica. Los bloques de código permanecen sin cambios. Los mensajes de error se citan exactamente. Los términos técnicos se mantienen intactos. El caveman solo habla el “envoltorio” en inglés alrededor de los hechos.
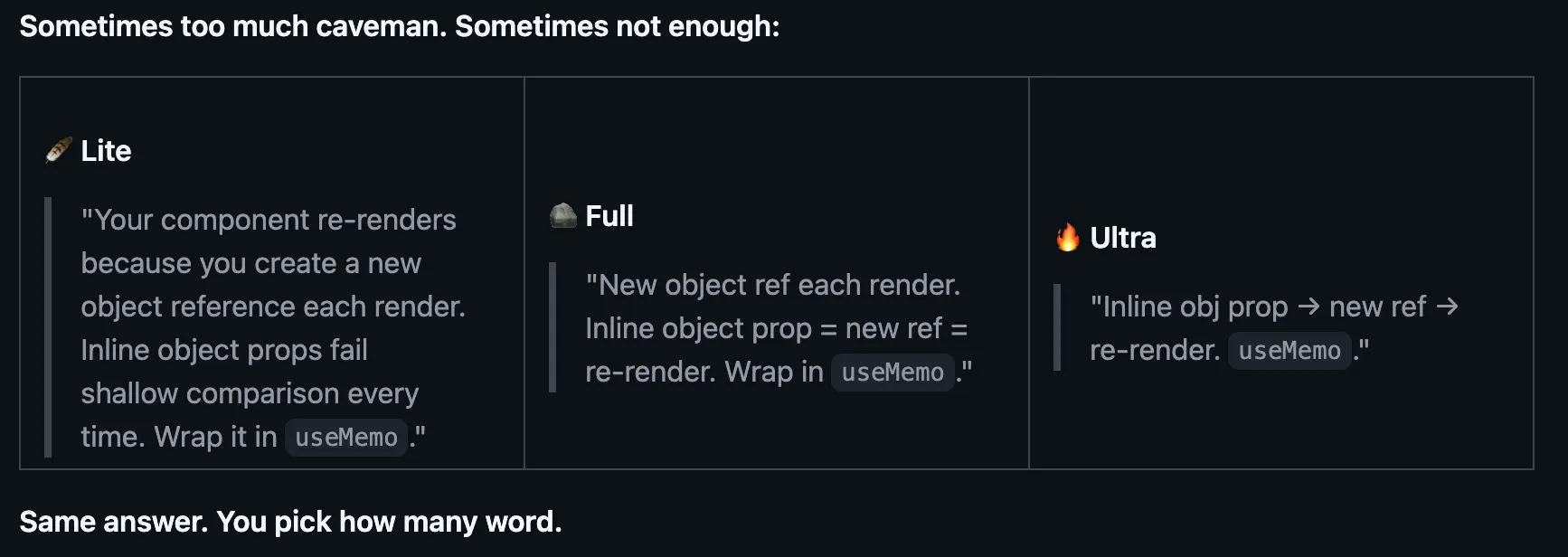
Este incluso incluye modos diferentes para afectar cuánto quieres recortar, cambiando entre Normal, Lite y Ultra. Los modelos hacen exactamente el mismo trabajo, pero proporcionan una respuesta mucho más corta, lo que se traduce en un gran ahorro con el tiempo.
El contexto más amplio de costos le da al chiste un filo más agudo. Anthropic está entre los modelos más caros en términos de precio por token. Para desarrolladores que ejecutan flujos de trabajo agentic con docenas de turnos por sesión, la verbosidad de salida no es una queja estilística. Es una partida presupuestaria. Si un gruñón de caveman puede reemplazar un resumen de cinco oraciones de lo que el modelo acaba de hacer, esos tokens ahorrados se van acumulando a través de miles de llamadas a la API.
La habilidad de caveman se puede instalar con un solo comando mediante skills.sh y funciona globalmente en todos los proyectos. Independientemente de si hace a Claude un poco menos elocuente, ya ha logrado que muchos desarrolladores estén significativamente menos molestos.
Aviso legal: La información de esta página puede proceder de terceros y no representa los puntos de vista ni las opiniones de Gate. El contenido que aparece en esta página es solo para fines informativos y no constituye ningún tipo de asesoramiento financiero, de inversión o legal. Gate no garantiza la exactitud ni la integridad de la información y no se hace responsable de ninguna pérdida derivada del uso de esta información. Las inversiones en activos virtuales conllevan riesgos elevados y están sujetas a una volatilidad significativa de los precios. Podrías perder todo el capital invertido. Asegúrate de entender completamente los riesgos asociados y toma decisiones prudentes de acuerdo con tu situación financiera y tu tolerancia al riesgo. Para obtener más información, consulta el
Aviso legal.

