- 置頂
- Gate.io 推薦話題每日發帖活動: #AI 概念币普涨#
💰 請帶上話題 #AI 概念币普涨# 發帖,5位優質發帖者*每人$10點卡獎勵
VIRTUAL 日內暴漲 40%, PIPPIN、COOKIE、AI16Z、GOAT 等其他AI 概念幣今日普漲。AI 概念幣仍是加密市場熱門賽道,你對 AI 概念幣交易有哪些見解?
帶上話題 #AI 概念币普涨# 發帖分享你的持倉策略或交易心得,參與瓜分 $50 獎勵!
📅 活動時間:4月29日12:00 - 4月30日12:00 (UTC+8)
⚠️ 注意事項:禁止抄襲,鼓勵原創內容
- 🌟 參與Gate.io動態內容挖礦,享受最高達10%的手續費返佣!💰
📌 如何參與:
1.發布動態:分享行情解析、交易觀點等優質內容。
2.獲取互動:吸引用戶點讚和評論您的帖子。
3.參與交易:在互動後180分鍾內進行現貨或合約交易。
4.收獲收益:成功交易後,您將獲得最高達10%的手續費返佣!
即刻發布:https://www.gate.io/post
詳情:https://www.gate.io/announcements/article/29944
- 🎈12周年慶典——限時狂歡派對首期正式開啓
參與贏iPhone16 Pro手機、Macbook Air等驚喜豪禮
✅ 登入即送免費遊戲機會,立即參與:https://www.gate.io/activities/12th-anniversary?pid=APP&ch=s9ZCIeg6
🎂 進入活動頁開啓遊,找到正確的12周年專屬慶典蛋糕,即可開出專屬驚喜獎勵
活動詳情:https://www.gate.io/announcements/article/44624
#Gateio12Years#
- 成長值第 🔟 期抽獎大狂歡火熱進行中!你今天參與抽獎了嗎?
立即抽獎,贏取MacBook Air和精美週邊!
👉 https://www.gate.io/activities/creditprize?now_period=10&pid=APP&ch=stu2ZKGn
🎁100%中獎,在動態完成成長值任務,抽取MacBook Air、Gate x 國際米蘭足球、合約體驗券、代幣、福袋、手續費返現券等!
截止於5月4日 24:00 UTC+8
更多: https://www.gate.io/announcements/article/44619
- 🎉 Gate.io動態 #创作者激励计划# 火熱進行中!報名參與並發帖解鎖 $2,000 創作大獎!
🌟 參與攻略:
1️⃣ 點擊連結進入報名頁面 👉️ https://www.gate.io/questionnaire/6550
2️⃣ 點擊“是”按鈕提交報名
3️⃣ 在動態完成發帖,提升發帖量和互動量,解鎖獲獎資格!
📌 只要是與加密相關內容均可參與發帖!
🎁 茶具套裝、Gate x 國際米蘭保溫杯、Gate.io 紀念章、點卡等好禮等你來拿!獲獎者還將獲得專屬社區流量扶持,助力您提升影響力,增長粉絲!
活動截止至:5月6日00:00 (UTC+8)
活動詳情:https://www.gate.io/announcements/article/44513
一文看懂共識機制和11 個主流共識算法
主講:宇智波斑
編輯:泡芙
來源:Deschool
本文為DeSchool 的web3 大學教程第三節課學習筆記,主講老師為宇智波斑。內容太乾絲毫不摻水,建議大家收藏起來慢慢消化。另外,為了方便理解,本文在課程內容基礎上有一定修改和補充。
文章主要內容包括:
共識算法簡介
共識算法分類
共識算法詳解( PoW, PoS, PoH, PoA, PBFT 等)
01共識機制簡介
在區塊鏈的交流和學習中,「共識算法」是一個很頻繁被提起的詞彙,正是因為共識算法的存在,區塊鏈的可信性才能被保證。
**1. 為什麼需要共識機制? **
所謂共識,就是多個人達成一致的意思。我們生活中充滿了共識機制,比如,一個公司要做決定需要股東們集體商量,簽合同需要甲方乙方坐下來協商。這個過程就是達成共識的過程。
在區塊鏈系統中,每個節點必須要做的事情就是讓自己的賬本跟其他節點的賬本達成一致。如果是在傳統的中心化場景中,這幾乎不是問題,因為有一個中心服務器存在,也就是所謂的主庫,其他的從庫向主庫看齊就行了。
但是在去中心化管理中,沒有老大的存在,那麼應該如何做出決定呢?這個時候就需要一套算法來保證達成共識。這就是本文要講的——共識機制。
**2. 什麼是共識機制? **
共識機制(Consensus Mechanism)是通過特殊節點的投票,在很短的時間內完成對交易的驗證和確認;對一筆交易,如果利益不相干的若干個節點能夠達成共識,我們就可以認為全網對此也能夠達成共識。
雖然共識(Consensus) 和一致性(Consistency) 在很多應用場景中被認為是近似等價的, 但二者涵義存在著細微的差別: 共識研究側重於分佈式節點達成一致的過程及其算法, 而一致性研究則側重於節點共識過程最終達成的穩定狀態; 此外, 傳統分佈式一致性研究大多不考慮拜占庭容錯問題, 即假設不存在惡意篡改和偽造數據的拜占庭節點。畢竟,在完全公開透明的區塊鍊網絡中,無法保證所有節點都不會作惡。
**3. 共識機制可以解決哪些問題? **
共識機制可以解決分佈式系統中的信任問題,確保各節點之間的數據一致性和安全性。在傳統的分佈式系統中,由於節點之間沒有信任機制,容易受到惡意節點的攻擊和篡改,導致系統崩潰或者數據被篡改。另外,在區塊鏈加密技術出現之前,加密數字貨幣和其他資產一樣,具有無限可複制性,如果沒有一個中心化的媒介機構,人們沒有辦法確認一筆數字現金是否已經被花掉。
簡單來講,共識機制可以有效解決兩個問題:雙花問題(一筆錢被花了兩次)和拜占庭將軍問題(惡意節點篡改數據)。
4. 雙花問題(Double spend attack)
** **
**
共識機制可以一定程度上解決雙花問題(double spend attack):即一筆錢被花了兩次或者兩次以上,也叫「雙重支付」。貓鼠遊戲中,小李子就通過做假支票進行了雙花行為,因為支票的驗證需要時間,所以在這個時間差內他多次用同一張支票的信息購買物品。
眾所周知,區塊鏈節點始終都將最長的鏈條視為正確的鏈條,並持續工作和延長它。如果有兩個節點同時廣播不同版本的新區塊,那麼將在率先收到的區塊基礎上進行工作,但也會保留另外一個鏈條,以防後者變成最長的鏈條。等到下一個工作量證明被發現,其中的一條鏈條被證實為是較長的一條,那麼在另一條分支鏈條上工作的節點將轉換陣營。
雙花是如何實現的呢?分為兩種情況:
**(1)在確認前的雙花。 **零確認的交易本來就可能最後沒有寫入區塊鏈。除非小額,最好至少等確認即可規避此類雙花。
**(2)在確認後的雙花。 **這就要控制超50% 算力才能實施。即類似於一個小分叉,將給一個商店的交易放入孤立區塊中。這種確認後雙花,很難實施,只是理論上可行。
**最常見的雙花攻擊有三種:51% 攻擊,競爭攻擊(Race Attack), 芬尼攻擊(Finney Attack)。 **
51% 攻擊:51% 攻擊是指一個人或者團體獲得了區塊鏈51% 的哈希運算能力的控制權,這意味著他們有能力控制項目的一些方面。在工作量證明區塊鏈(如比特幣)上,這將通過獲得網絡採礦能力的控制權來實現。另一方面,對於權益證明區塊鏈(如Cardano),這將通過控制51% 的抵押代幣來實現。
競賽攻擊:一個用戶同時向兩個商家( 或者商家和用戶本身) 發送兩筆交易。因此,攻擊者會收到兩組貨物或者收到貨物和回收了原始交易成本。
芬尼攻擊:一個礦工挖到一個或者一系列的塊,這些塊裡包含他把錢轉賬給自己其它地址的交易。被挖到的塊沒有被公佈,而是在礦工向商家轉賬時被保留。然後,商人在礦工公佈他們已經挖出的區塊之前釋放了礦工所支付的貨物。隨後礦工公佈已經挖出的區塊,這就會抹掉轉賬給商家的交易,讓商家自掏腰包。
雙花攻擊經典案例:
2018 年,攻擊者控制BTG 網絡上51% 以上的算力,控制算力期間,把一定數量的BTG 發給自己在交易所的錢包,這條分支命名為分支A。同時,又把這些BTG 發給另一個自己控制的錢包,這條分支命名為分支B。分支A 上的交易被確認後,攻擊者立馬賣掉BTG,拿到現金。隨後,攻擊者在分支B 上進行挖礦,由於其控制了51% 以上的算力,很快分支B 的長度就超過了分支A 的長度,分支B 就會成為主鏈,分支A 上的交易就會被回滾恢復到上一次的狀態。攻擊者之前換成現金的那些BTG 又回到了自己手裡,這些BTG 就是交易所的損失。這樣,攻擊者就憑藉50% 以上的算力控制,實現了同一筆加密貨幣的「雙花」。
5. 拜占庭將軍問題(Byzantine failures)
** **
**
拜占庭將軍問題是Leslie Lamport 在10 世紀80 年代提出的一個假想問題。拜占庭是東羅馬帝國的首都,由於當時拜占庭羅馬帝國國土遼闊,每支軍隊的駐地分隔很遠,將軍們只能靠信使傳遞消息。發生戰爭時將軍們必須制定統一的行動計劃。
然而,這些將軍中有叛徒,叛徒希望通過影響統一行動計劃的製定與傳播,破壞忠誠的將軍們一致的行動計劃。因此,將軍們必須有一個預定的方法協議,使所有忠誠的將軍夠達成一致。而且少數幾個叛徒不能使忠誠的將軍做出錯誤的計劃。也就是說,拜占庭將軍問題的實質就是要尋找一個方法,使得將軍們在一個有叛徒的非信任環境中建立對戰鬥計劃的共識。
在分佈式系統中,特別是在區塊鍊網絡環境中,也和拜占庭將軍的環境類似,有運行正常的服務器(類似忠誠的拜占庭將軍),還有故障的服務器,有破壞者的服務器(類似叛變的拜占庭將軍)。共識算法的核心是在正常的節點間形成對網絡狀態的共識。如果只有3 個節點的話,拜占庭將軍問題是無解的,當節點中有x 個問題節點,而總結點數小於3x+1 時,拜占庭將軍問題無解。
比特幣的出現輕而易舉地解決了這一問題,它為信息發送加入了成本,降低了信息傳遞的速率,而且加入了一個隨機元素使得在一定時間內只有一個將軍可以廣播信息。第一個廣播信息的將軍就是第一個發現有效哈希值的計算機,只要其他將軍接收到並驗證通過了這個有效哈希值和附著在上面的信息,他們就只能使用新的信息更新他們的總賬複製,然後重新計算哈希值。下一個計算出有效哈希值的將軍就可以將自己再次更新的信息附著在有效哈希值上廣播給大家。然後哈希計算競賽從一個新的開始點重新開始。由於網絡信息的持續同步,所有網絡上的計算機都使用著同一版本的總賬。
02共識算法分類
1. 共識機制的歷史
當計算機和網絡在1980 年代和90 年代開始流行時,出現了了共享數據庫,以便多個用戶可以訪問他們存儲的信息。大多數都有一個中央數據庫,用戶可以從不同的站點訪問權限。這種設置演變成中心化網絡,管理員授予用戶權限並維護數據的完整性。
這些共享數據庫被稱為分佈式賬本,因為它們記錄信息並聯網供不同位置的許多用戶訪問。需要解決的最重要的問題之一是防止數據篡改和未經授權的訪問,無論是否是惡意的。需要一種自動化分佈式數據庫管理的方法來確保數據不被更改。
這種需求導致了分佈式自治共識的產生,其中網絡上的程序使用加密技術就數據庫的狀態達成一致。協議旨在通過使用加密算法來創建一長串字母數字數(哈希)來達成,然後由網絡上運行的程序進行驗證。只有當輸入到哈希算法的信息發生變化時,哈希才會發生變化,因此程序被設計為比較哈希以確保它們匹配。
當網絡上運行的每個程序都創建了一個匹配的哈希字符串,就可以說該數據已通過網絡達成共識。因此,建立了共識機制,通常將信用歸功於匿名比特幣創建者中本聰。然而,在中本聰發布讓比特幣出名的白皮書之前,許多人在共識機制上工作了多年。
Moni Naor、Cynthia Dwork、Adam Beck、Nick Szabo 等數據和計算機科學家以及許多其他人致力於開發網絡共識機制並做出貢獻。
2共識算法的分類
根據容錯類型的不同,共識算法可以分為兩大類:CFT 類共識算法( 非拜占庭容錯,即不考慮惡意節點) 和BFT 類共識算法(拜占庭容錯,也就是說考慮惡意節點)。
是否容忍拜占庭標誌著該算法是否能夠應用到低信任的網絡當中。通常來說,公有鏈環境中必須使用拜占庭容錯算法,而聯盟鏈中可以根據聯盟參與方之間的信任程度進行選擇,信任程度高默認大家都是善意節點就可以使用CFT 類算法(非拜占庭容錯)。
**另外可以根據一致性被分為兩大類:**概率一致性算法和絕對一致性算法。概率一致性算法指在不同分佈式節點之間,有較大概率保證節點間數據達到一致,但仍存在一定概率使得某些節點間數據不一致。例如工作量證明算法(Proof of Work, PoW)、股份證明算法(Proof of Stake, PoS)和委託股權證明算法(Delegated Proof of Stake, DPoS)都屬於概率一致性算法。
絕對一致性算法則指在任意時間點,不同分佈式節點之間的數據都會保持絕對一致,不存在不同節點間數據不一致的情況。例如PAXOS 算法及其衍生出的RAFT 算法。
下文根據容錯類型進行具體劃分和介紹。
3CFT 類共識算法
Crash Fault Tolerance 非拜占庭錯誤:適用於節點信任程度高的網絡。包括Paxos, Raft。
4BFT 類共識算法
檢查節點是否具有惡意的拜占庭錯誤傾向於去中心化的結構,包括工作量證明(PoW),權益證明(PoS), 委託權益證明(DPoS), 權威證明(PoA)等。
03共識算法詳解
看到這裡是不是已經有點累了,點個收藏,休息一會繼續來啃本文最硬核的部分吧!時間有限的同學可以直接從第三個PoW 算法開始看。
1Paxos 算法
**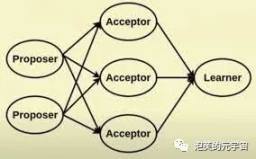 **
**
早期的Basic Paxos 協議複雜,且效率相對較低,所以在後來提出了Paxos 的改進版本。比如:Fast Paxos, Multi-Paxos 以及Byzanetine Paxos 等。
Paxos 通過一組協商回合進行,其中一個節點具有「領導」狀態。如果領導者不在線,進展將停滯,直到選出新的領導者,或者如果舊領導者突然重新上線。
Paxos 將系統中的角色分為提議者(Proposer),決策者(Acceptor),和最終決策學習者(Learner):Proposer: 提出提案(Proposal)。 Proposal 信息包括提案編號(Proposal ID) 和提議的值(Value)。 Acceptor:參與決策,回應Proposers 的提案。收到Proposal 後可以接受提案,若Proposal 獲得多數Acceptors 的接受,則稱該Proposal 被批准。 Learner:不參與決策,從Proposers/Acceptors 學習最新達成一致的提案(Value)。
2. Raft 算法
**算法簡介:**Raft(Replication and Fault Tolerant) 算法是Paxos 算法對的一種簡化實現,Raft 這一名字來源於「Reliable, Replicated, Redundant, And Fault-Tolerant」(「可靠、可複制、可冗餘、可容錯」)的首字母縮寫。 raft 利用日誌連續性對Paxos 做了大量很好的簡化。它保證了在一個由n 個節點構成的系統中有超過一半的節點正常工作的情況下的系統的一致性。不同於Paxos 算法直接從分佈式一致性問題出發推導出來,Raft 算法則是從多副本狀態機的角度提出,用於管理多副本狀態機的日誌複製。比如在一個5 個節點的系統中允許2 個節點出現非拜占庭錯誤,如節點宕機,網絡分區,消息延時。
**使用案例:**數據庫主從復制,聯盟鏈。
**算法原理:**Raft 系統中有三種角色:領袖(Leader), 追隨者(Follower),候選人(Candidate)在正常情況下只會有一個領袖,其他都是追隨者。而領袖會負責所有外部的請求,如果不是領袖的機器收到時,請求會被導到領袖。通常領袖會藉由固定時間發送消息,也就是心跳(heartbeat),讓追隨者知道集群的領袖還在運作。而每個追隨者都會設計超時機制(timeout),當超過一定時間沒有收到心跳(通常是150 ms 或300 ms),系統就會進入選舉狀態。
此時集群進入新的競選輪次(term)並開始選舉,如果選舉成功則新的領袖開始執行工作,反之則視此任期終止,開始新的任期並開始下一場選舉。
選舉是由候選人發動的。當領袖的心跳停止的時候,這需要候選者以先到先得的方式提名自己,並向其他服務器拉票。每個服務器在每個競選輪次只會投一票表示支持或反對當前候選人。如果沒有獲得過半的選票就進入下一輪競選。其餘候選者繼續根據先到先得提名自己。直到選出領袖。
**Raft 算法的優越性:**第一點是簡單性。如果深入挖掘Paxos 到底比Raft 複雜在哪裡,Heidi Howard 和Richard Mortier 發現在兩個方面體現了Paxos 的複雜性。第一,Raft 按順序提交日誌,而Paxos 允許日誌不按順序提交,但需要一個額外的協議來填補可能因此而出現的日誌空洞。第二,Raft 中的所有日誌的副本都有相同的索引、任期和命令,而Paxos 中這些任期可能有所不同。
第二點是Raft 具備了一個高效的領導者選舉算法。 Paxos 論文中給出的選舉算法是通過比較服務器id 的大小,幾個節點同時競選時,服務器id 較大的節點勝出。問題是,這樣選出的領導者如果缺少一些日誌,它不能立即執行寫操作,必須首先從別的節點那裡複製一些日誌。 Raft 日誌總能選出擁有多數派日誌的節點,從而不需要追趕日誌,雖然有時候選舉會因為瓜分選票而重試,但總體來說是一個更有效率的選舉算法。
對於Paxos 算法,如果一個服務器非常落後,甚至落後了幾天的日誌,但卻在某個時候選為了領導者,這將導致一定時間的阻塞。可在Raft 算法中,永遠不會選出日誌落後的節點。
3工作量證明(Proof of Work, PoW)
**算法簡介:**最早用來對抗垃圾郵件的一種計算機技術。 2008 年,中本聰在《比特幣:一種點對點的電子現金系統》比特幣白皮書中提出了比特幣與區塊鏈,創新的設計了PoW 算法,被應用在比特幣上,用來解決一個數學難題來參與共識。算法的核心內容是利用算力來尋找一個滿足區塊哈希的nonce 值。但是人們很快發現這種共識機制的問題,即能耗大,以及被大礦池把持算力之後,仍然會導致中心化問題。
**使用案例:**Bitcoin, ETH1.0, Litecoin, Conflux, Dogecoin。
**算法原理:**工作量證明系統主要特徵是客戶端需要做一定難度的工作得出一個結果,驗證方卻很容易通過結果來檢查客戶端是不是做了相應的工作。這種方案的一個核心特徵是不對稱性:工作對於請求方是適中的,對於驗證方是易於驗證的。它與驗證碼不同,驗證碼的設計出發點是易於被人類解決而不是被計算機解決。
工作量證明(PoW)通過計算尋找一個數值Nonce,使得拼湊上交易數據後內容的hash 值滿足規定的上限。在節點成功找到滿足的hash 值後,會馬上對全網進行廣播打包區塊,網絡的節點收到廣播打包區塊,會立刻對其進行驗證。
**缺點:**速度慢;耗能巨大,對環境不好;易受「規模經濟」(economies of scale)的影響。
**優點:**自2009 年以來得到了廣泛測試,目前依然得到廣泛的使用。
4權益證明(Proof of Stake, PoS)
**算法簡介:**2011 年,Quantum 在Bitcointalk 論壇上提出。 2012 年8 月,首個基於PoS 共識的區塊鏈項目點點幣(Peercoin)誕生,點點幣(Peercoin)是第一個實現PoS 算法的應用。點點幣中權益即為幣齡,幣齡是節點所持幣的數量與其持有時間的乘積,發起交易會消耗一定的幣齡,每消耗365 幣齡時也將獲得年利率5% 的利息。
使用者: Ethereum(2.0), Conflux, Peercoin。
**算法原理:**例如某人在一筆交易中持有點點幣100 個,共持有30 天,那麼幣齡為3000,後來發現了一個PoS 塊,幣齡被清空為0,獲得利息為0.05*3000/365=0.41 幣。共識過程中節點通過消耗的幣齡來獲取記賬權,節點消耗的幣齡越多,獲得記賬權的機會越大。算法設定的主鏈原則為:消耗幣齡最多的鍊為系統中正確有效的鏈。
**優點:**不需要強大、昂貴的挖礦設備。減少資源消耗,減少51% 攻擊的可能性。
**缺點:**可能導致富人囤積加密貨幣,形成馬太效應,可能產生加密貨幣通脹問題。
5歷史證明(Proof of History, PoH)
**算法簡介:**歷史證明是Solana 創建,這是一個高吞吐量區塊鏈,於2018 年啟動,歷史證明使網絡參與者可以通過使用可驗證的延遲功能在時間上達成共識,從而避免了「最長鏈」規則。
PoH 是網絡的時鐘,而TowerBFT 是其守望台,其任務是防止惡意節點欺騙時間參數。對某個區塊進行投票的任何驗證者都必須等待下一個區塊的產生,並從歷史證明中獲得「時間已經過去」的確認,然後才能再次投票。
Solana 則巧妙將基於哈希的時間鍊和狀態分離,不是將每個區塊的哈希鏈接在一起,而是網絡中驗證者對於區塊內的哈希本身進行哈希,這種機制就是PoH。 PoH 通過使用高頻可驗證延遲函數(VDF),隨著時間的推移建立可通過密碼驗證的事件順序。從本質上講,這意味著PoH 就像一個加密時鐘,可以幫助網絡就時間和事件順序達成一致,而無需等待其他節點的消息。歷史證明的區塊鏈狀態哈希的連續輸出能夠給出可驗證的事件順序。
**使用者:**Solana
算法原理: Leader 給每個簽名數據(待證明的交易)生成一個時間戳,直接將交易排序,這樣就避免了PoS 中時間排序的問題,每個保證驗證者都可以獨立進行驗證,這樣大大縮短了驗證時時間重排序的問題,只要進行交易證明的驗證即可。
優點:費用低,每筆交易的費用只有幾分之一美分,交易速度快,可延展性好,
**缺點:**中心化的擔憂,Solana 目前有不到1200 個驗證者來驗證其網絡上的交易。更少的去中心化應用程序:常被稱為以太坊殺手。根據其網站,在Solana 上創建了350 多個Dapp,相比之下以太坊上有近3000 個Dapp,而這正是Defi 目前需要更多開發時間和創新的地方。
6權威證明(Proof of Authority, PoA)
算法簡介:由以太坊(ETH)和Parity Technologies 公司的聯合創始人Gavin Wood 於2017 年提出。 PoA 機制不挖礦也不需要Token。在基於次PoA 的區塊鍊網絡中,所有的交易和區塊均由驗證人處理。 PoA 平台維護成本低,但是在PoA 中,交易和驗證區塊鏈的驗證人,必須是能通過可靠性審查的人。所以,PoA 的驗證人必須非常關注自身聲譽。聲譽在PoA 裡就是非常重要的資產。一般情況下,驗證人會公開自己的實際身份。目前,這種共識機制形成的區塊鏈技術主要應用在行業特徵明顯的聯盟鏈、私有鏈上。
使用者: PoA、 Ethereum Kovantestnet、 xDai、 VeChain 和沃爾瑪的物流鏈。
算法原理:
a. 選擇權威證明者;
b.由若干個驗證人來生成區塊記錄交易,並獲得區塊獎勵和交易費用。在PoA 中,驗證者是整個共識機制的關鍵,驗證者通過放置這個身份來獲得擔保網絡的權利,從而換取區塊獎勵。若是驗證者在整個過程中有惡意行為,或與其他驗證者勾結,那通過鏈上管理可以移除和替換惡意行為者。現有的法律反欺詐保障會被用於整個網絡的參與者免受驗證者的惡意行為。
優點:
a. 需要更少的算力,不需要挖礦,節能環保;
b驗證速度快,支持更快的事務;
c. 整個網絡驗證者互相監督,隨時可以投票加入心得驗證者或者剔除不合格驗證者
d. 硬分叉受法律保護,每個Validator 均簽訂法律協議。
缺點:
a. 公開身份,隱私和匿名性將減少
b. 驗證人特定為法律支持的集中的權威節點
**7延遲工作量證明(**Delayed Proof-of-Work, dPoW)
** **
**
**算法簡介:**解釋DPoW 前,需要先說明什麼叫PoB。 PoB(Proof of Burn)叫做焚燒證明機制,是一種通過焚燒自己手中的代幣來表決誰擁有對網絡的領導地位的承諾。焚燒代幣的數量越多,獲得網絡領導地位的概率越高。
在基於dPoW 的區塊鏈中,礦工挖礦所獲得的不再是獎勵的代幣,而是可以焚燒的「wood」——燃木。礦工使用自己的算力,通過哈希算法,最終證明自己的工作量之後,獲取對應的wood,wood 不可交易。當wood 積攢到一定量之後,可以前往燃燒場地燃燒wood。
通過一組算法計算後,燃燒較多wood 的人或者BP 或者一組BP 可以獲取下個事件段出塊的權利,成功出塊後獲取獎勵(Token)。由於一個時間段內可能會有多人燃燒wood,下一個時間段出塊的概率由自己燃燒wood 數量決定。焚燒的越多,下一段時間可以獲得出塊權利的概率越高。
這樣可以讓算力和出礦權利達到一個平衡。不一定非要龐大算力的礦工、礦池才能成為區塊生產者。小礦工也有春天,只要辛勤勞動,積攢一定數量的wood,也能出塊。保證效率,人人參與,最平民化的參與方式保證了去中心化的理念,避免擁有算力的組織或者持幣大戶把持網絡。
**使用者:**Komodo
**算法原理:**dPoW 系統中有兩種類型的節點:公證人節點和正常節點。 64 個公證人節點是由dPoW 區塊鏈的權益持有者(stakeholder)選舉產生的,它們可從dPoW 區塊鏈向所附加的PoW 區塊鏈添加經公證確認的塊。一旦添加了一個塊,該塊的哈希值將被添加到由33 個公證人節點簽署的Bitcoin 交易中,並創建一個哈希到Bitcoin 區塊鏈的dPow 塊記錄。該記錄已被網絡中的大多數公證人節點公證。
為避免公證人節點間在挖礦上產生戰爭,進而降低網絡的效率,Komodo 設計了一種採用輪詢機制的挖礦方法,該方法具有兩種運行模式。
在「无公证人」(No Notary)模式下,支持所有网络节点参与挖矿,这类似于传统 PoW 共识机制。而在「公证人激活」(Notaries Active)模式下,网络公证人使用一种显著降低的网络难度率挖矿。「公证人激活」模式下,允许每位公证人使用其当前的难度挖掘一个区块,而其它公证人节点必须采用 10 倍难度挖矿,所有正常节点使用公证人节点难度的 100 倍挖矿。
**優點:**節能;安全性增加;可以通過非直接提供Bitcoin(或是其它任何安全鏈),添加價值到其它區塊鏈,無需付出Bitcoin(或是其它任何安全鏈)交易的代價。
**缺點:**只有使用PoW 或PoS 的區塊鏈,才能採用這種共識算法;在「公證員激活」(Notaries Active)模式下,必須校準不同節點(公證員或正常節點)的哈希率,否則哈希率間的差異會爆炸。
8授權PoS(DPoS,Delegated Proof-of-Stake)
**算法簡介:**DPoS 機制,又叫做「股份授權證明機制」和「受託人機制」,是2014 年4 月由Bitshares 的首席開發者Dan Larimer(BM)提出的。從某種角度來看,DPOS 有點像是議會制度或人民代表大會制度。如果代表不能履行他們的職責(當輪到他們時,沒能生成區塊),他們會被除名,網絡會選出新的超級節點來取代他們。
為了方便理解,可以再舉個例子。想像有這樣一家公司:公司員工總數有1000 人,每個人都持有數額不等的公司股份。每隔一段時間,員工可以把手裡的票投向自己最認可的10 個人來領導公司,其中每個員工的票權和他手裡持有的股份數成正比。等所有人投完票以後,得票率最高的10 個人成為公司的領導。
如果有領導能力不勝任或做了不利於公司的事,那員工可以撤銷對該領導的投票,讓他的得票率無法進入前10 名,從而退出管理層。
**使用者:**BitShares、Steemit、EOS、Lisk、Ark。
**優點:**節能;快速;高流量博客網站Steemit 就使用了它。 EOS 的塊時間是0.5 秒。
**缺點:**略中心化;擁有高權益的參與者可投票使自己成為一名驗證者(這是近期已在EOS 中出現的問題)。
9實用拜占庭容錯(Practical Byzantine Fault Tolerance, PBFT)
** **
**
**算法簡介:**PBFT 算法中,有一個節點會被當做主節點,而其他節點都是備份節點。系統內的所有節點都會相互通信,最終目標是大家能以少數服從多數的原則達成共識。
共識過程:
a. 客戶端發送一個請求給主節點去執行某個操作
b. 主節點廣播這個請求到各個備份節點
c. 所有節點執行操作並把結果返回客戶端
d. 當客戶端收到f+1 個來自不同節點的相同的結果後,過程結束。 f 代表可能撒謊的節點的最大值。
使用者: HyperLedgerFabric、Stellar、Ripple、Dispatch
**優點:**高速、可擴展。
**缺點:**通常用於私有網絡和許可網絡。
10授權拜占庭容錯(dBFTDelegated Byzantine Fault Tolerance,dBFT)
**算法簡介:**中國區塊鏈社區NEO ( 原名小蟻) 提出一種改進的拜占庭容錯算法dBFT, 該算法在PBFT 的基礎上借鑒了PoS 設計思路, 首先按照節點的權益來選出記賬人, 然後記賬人之間通過拜占庭容錯算法來達成共識。該算法改進了PoW 和PoS 缺乏最終一致性的問題, 使得區塊鏈能夠適用於金融場景。
同樣是為了解決拜占庭將軍問題,「授權拜占庭容錯」機制,是一種在NEO 區塊鏈內部實現的保證容錯的共識算法。在這個機制當中,存在兩個參與者,一個是專業記賬的「記賬節點」,一個是系統當中的普通用戶。
普通用戶基於持有權益的比例來投票決定記賬節點,當需要通過一項共識時,在這些記賬節點中隨機推選出一名發言人擬定方案,然後由其他記賬節點根據拜占庭容錯算法,即少數服從多數的原則進行表態,如果超過66% 的節點表示同意發言人方案,則共識達成;否則,重新推選發言人,重複投票過程。
由於所有代表都可以驗證區塊提案,因此很容易理解議長發送的數據是有效還是無效。因此,如果議長不誠實並向三分之二的代表發送無效提案,則塊將不匹配,節點所有者將不會對其進行驗證。以三分之二的票數達成共識,並選出新的議長。
**使用者:**Neo
共識過程:
a. 任何人都可以成為代表,只要他或她符合要求。所有NEO 代幣持有者都可以投票,代表不是匿名的,並且成為節點所有者需要1,000 GAS。
b. 從代表中隨機選出一名發言人。
c. 發言人從等待驗證的交易中構建一個新區塊。然後,議長將提案發送給當選的代表。他們應該跟踪所有交易並將它們記錄在網絡上。
d. 代表們可以自由分享和比較他們收到的提案,以測試數據的準確性以及演講者的誠實度。如果超過三分之二的代表達成共識並驗證,則該區塊被添加到區塊鏈中。
**優點:**快速( 生成一個塊需要15-20 秒);交易吞吐量大,無需消耗能量,可擴展,沒有分叉。
**缺點:**沒有匿名性,需要真實身份運作才能被選舉。每個人都爭相成為根鏈。其中可能存在多個根鏈。
11. 輪流拜占庭容錯(Rotation Practical Byzantine Fault Tolerance, RBPFT)
**算法簡介:**dBft 和RPBFT 原理和PBFT 相似,只是不是所有的節點都參與共識,而是將節點分為兩種:
a. 共識節點:執行PBFT 共識流程的節點,有輪流出塊的權限
b. 驗證節點:不執行共識流程,驗證共識節點是否合法、區塊驗證,經過若干輪共識後,會切換為共識節點
輪流拜占庭容錯中輪流將共識節點替換為驗證節點。
**使用案例:**Fisco-BCOS
**優點:**傳播速度比gossip 快,無冗餘消息包
分而治之,每個節點出帶寬為O(1),可擴展性強
**缺點:**中間節點是單點,需要額外的容錯策略
12。 AptosBFT
** **
**
**算法簡介:**也是PBFT 的衍生算法,Aptos 以名字命名的共識算法,基於HotStuff, 而HotStuff 又基於PBFT。這個算法模型優點像洋蔥和俄羅斯套娃,需要一層一層剝開。每個節點只與領導者通信,而不是向領導者和其他所有「將軍」發送消息。領導者廣播要投票的消息(建議的塊);每個節點將其投票發送給收集消息的領導者。
**使用案例:**Aptos
最後,附上本部分大總結:
**此外,還有一些不常見的共識算法。 **
2015 年, Stellar.org 首席科學官David Mazieres 教授提出了恆星共識協議(Stellar consensus protocol, SCP). SCP 在聯邦拜占庭協議和Ripple 協議的基礎上演化而來的, 是第一個可證明安全的共識機制, 具有分散控制、低延遲、靈活信任和漸近安全4 個關鍵屬性。
同年, 超級賬本的鋸齒湖項目將Ripple 和SCP 共識相結合, 提出了法定人數投票(Quorum voting) 共識算法, 以應對那些需要即時交易最終性的應用場景。
2016 年, 圖靈獎得主、MIT 教授Sivio Micali 提出了一種稱為AlgoRand 的快速拜占庭容錯共識算法. 該算法利用密碼抽籤技術選擇共識過程的驗證者和領導者, 並通過其設計的BA* 拜占庭容錯協議對新區塊達成共識. AlgoRand 只需極小計算量且極少分叉, 被認為是真正民主和高效的分佈式賬本共識技術。
2017 年, 康奈爾大學提出了一種稱為Sleepy Consensus ( 休眠共識) 的新算法. 這種共識針對的是互聯網環境下大規模的共識節點中可能多數都處於離線狀態, 僅有少數節點在線參與共識過程的實際情況。該研究證明, 傳統共識算法無法在這種環境下保證共識的安全性. 而採用休眠共識算法, 只要在線誠實節點的數量超過故障節點的數量, 即可保證安全性和魯棒性。
04總結
如果跳出開發者的角度,更多結合政治與經濟的思考方式在裡面,或許還會出現更多的共識算法,如結合類似PPP 概念的共識方式,不僅能達到對惡意者的懲罰性質,還能達到最高效節約算力的目的也說不定。
總之,共識機制是區塊鏈技術的核心,它可以解決分佈式系統中的信任問題,確保各節點之間的數據一致性和安全性,避免了惡意節點的攻擊和篡改,從而保證了區塊鏈系統的穩定性和可信度。同時,共識機制還可以解決「雙花」問題,提高區塊鏈系統的吞吐量和處理速度。但是各種共識算法並不是絕對安全,高效,去中心化的。
沒有最好的算法,只有最適合自己的算法。共識算法的選擇與應用場景高度相關,可信環境使用Paxos 或者RAFT,帶許可的聯盟可使用PBFT ,非許可鏈可以是PoW,PoS,Ripple 共識等。 **最好的共識機制永遠是適合用戶需求的機制。 **