The cryptocurrency market is known for its extreme volatility, presenting significant opportunities for investors, but also considerable risks. Accurate price prediction is crucial for informed investment decisions. However, traditional financial analysis methods often struggle to cope with the complexity and rapid shifts of the crypto market. In recent years, the advancement of machine learning has provided powerful tools for financial time series forecasting, particularly in cryptocurrency price prediction.
Machine learning algorithms can learn from large volumes of historical price data and other relevant information, identifying difficult patterns for humans to detect. Among various machine learning models, Recurrent Neural Networks (RNNs) and their variants, such as Long Short-Term Memory (LSTM) and Transformer models, have gained wide attention for their exceptional ability to handle sequential data, showing increasing potential in crypto price forecasting. This article offers an in-depth analysis of machine learning-based models for cryptocurrency price prediction, focusing on comparing LSTM and Transformer applications. It also explores how integrating diverse data sources can enhance model performance and examines the impact of black swan events on model stability.
Application of Machine Learning in Cryptocurrency Price Prediction
The fundamental idea of machine learning is to enable computers to learn from large datasets and make predictions based on the learned patterns. These algorithms analyze historical price changes, trading volumes, and other related data to uncover hidden trends and patterns. Common approaches include regression analysis, decision trees, and neural networks, all of which have been widely used in building cryptocurrency price prediction models.
Most studies relied on traditional statistical methods in the early stages of cryptocurrency price forecasting. For example, around 2017, before deep learning became widespread, many studies used ARIMA models to predict the price trends of cryptocurrencies like Bitcoin. A representative study by Dong, Li, and Gong (2017) utilized the ARIMA model to analyze Bitcoin volatility, demonstrating the stability and reliability of traditional models in capturing linear trends.
With technological advancements, deep learning methods began to show breakthrough results in financial time series forecasting by 2020. In particular, Long Short-Term Memory (LSTM) networks gained popularity due to their ability to capture long-term dependencies in time series data. A study by Patel et al. (2019) proved the advantages of LSTM in predicting Bitcoin prices, marking a significant advancement at the time.
By 2023, Transformer models—with their unique self-attention mechanisms capable of capturing relationships across the entire data sequence at once—were increasingly applied to financial time series forecasting. For instance, Zhao et al.’s 2023 study “Attention! Transformer with Sentiment on Cryptocurrencies Price Prediction” successfully integrated Transformer models with social media sentiment data, significantly improving the accuracy of cryptocurrency price trend predictions, marking a major milestone in the field.

Milestones in Crypto Prediction Technology (Source: Gate Learn Creator John)
Among the many machine learning models, deep learning models—particularly Recurrent Neural Networks (RNNs) and their advanced versions, LSTM and Transformer—have demonstrated significant advantages in handling time series data. RNNs are specifically designed to process sequential data by passing information from earlier steps to later ones, effectively capturing dependencies across time points. However, traditional RNNs struggle with the “vanishing gradient” problem when dealing with long sequences, causing older but important information to be gradually lost. To address this, LSTM introduces memory cells and gating mechanisms on top of RNNs, enabling long-term retention of key information and better modeling long-term dependencies. Since financial data, such as historical cryptocurrency prices, exhibits strong temporal characteristics, LSTM models are particularly well-suited for predicting such trends.
On the other hand, Transformer models were originally developed for language processing. Their self-attention mechanism allows the model to consider relationships across the entire data sequence simultaneously, rather than processing them step by step. This architecture gives Transformers immense potential in predicting financial data with complex temporal dependencies.
Comparison of Prediction Models
Traditional models like ARIMA are often used as baselines alongside deep learning models in cryptocurrency price prediction. ARIMA is designed to capture linear trends and consistent proportional changes in data, performing well in many forecasting tasks. However, due to the highly volatile and complex nature of cryptocurrency prices, the linear assumptions of ARIMA often fall short. Studies have shown that deep learning models generally provide more accurate predictions in nonlinear and highly fluctuating markets.
Among deep learning approaches, research comparing LSTM and Transformer models in predicting Bitcoin prices found that LSTM performs better when capturing the finer details of short-term price changes. This advantage is primarily due to LSTM’s memory mechanism, which enables it to model short-term dependencies more effectively and stably. While LSTM may outperform in short-term forecasting precision, Transformer models remain highly competitive. When enhanced with additional contextual data—such as sentiment analysis from Twitter—Transformers can offer a broader market understanding, significantly improving predictive performance.
Moreover, some studies have explored hybrid models that combine deep learning with traditional statistical approaches, such as LSTM-ARIMA. These hybrid models aim to capture both linear and nonlinear patterns in the data, further enhancing prediction accuracy and model robustness.
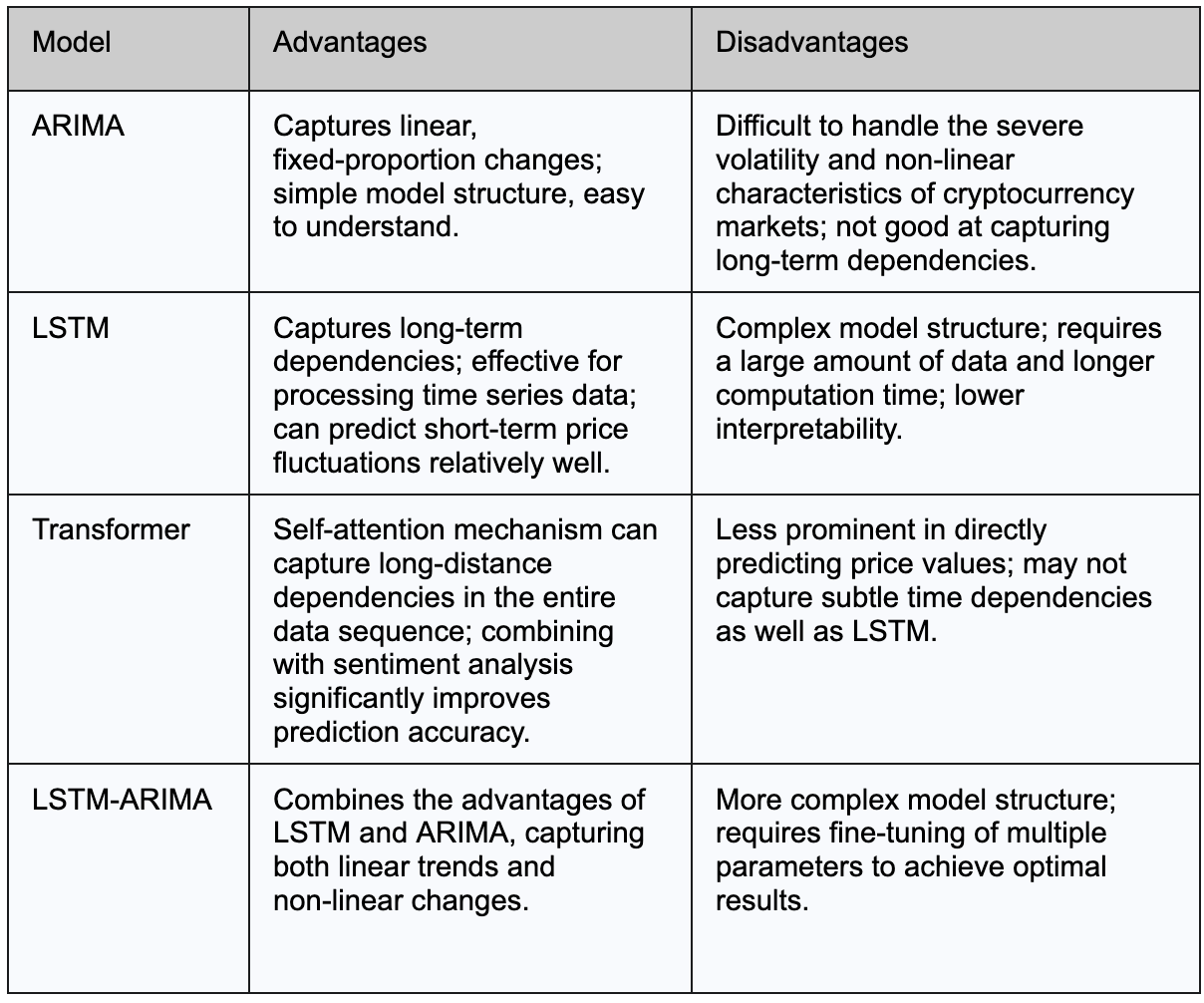
The table below summarizes the key advantages and disadvantages of ARIMA, LSTM, and Transformer models in Bitcoin price prediction:
Improving Prediction Accuracy with Feature Engineering
When forecasting cryptocurrency prices, we don’t rely solely on historical price data—we also incorporate additional valuable information to help models make more accurate predictions. This process is called feature engineering, which involves organizing and constructing data “features” that enhance prediction performance.
Common Feature Data Sources
On-chain Data
On-chain data refers to all transactional and activity information recorded on the blockchain, including trading volume, number of active addresses, mining difficulty, and hash rate. These metrics directly reflect market supply and demand dynamics and overall network activity, making them highly valuable for price forecasting. For instance, a significant spike in trading volume may signal a shift in market sentiment, while an increase in active addresses could indicate broader adoption, potentially pushing prices upward.
Such data is typically accessed via blockchain explorer APIs or specialized data providers like Glassnode and Coin Metrics. You can use Python’s requests library to call APIs or directly download CSV files for analysis.
Social Media Sentiment Indicators
Platforms like Santiment analyze text content from sources such as Twitter and Reddit to assess market participants’ sentiment toward cryptocurrencies. They further apply natural language processing (NLP) techniques like sentiment analysis to convert this text into sentiment indicators. These indicators reflect investor opinions and expectations, offering valuable input for price prediction. For instance, predominantly positive sentiment on social media may attract more investors and push prices up, while negative sentiment could trigger selling pressure. Platforms like Santiment also provide APIs and tools to help developers integrate sentiment data into prediction models. Studies have shown that incorporating social media sentiment analysis can significantly enhance the performance of crypto price prediction models, especially for short-term forecasts.

Santiment can provide sentiment data on market participants’ views of cryptocurrencies (Source: Santiment)
Macroeconomic Factors
Macroeconomic indicators such as interest rates, inflation rates, GDP growth, and unemployment rates also influence cryptocurrency prices. These factors affect investors’ risk preferences and capital flows. For example, investors may shift funds from high-risk assets like cryptocurrencies to safer alternatives when interest rates rise, leading to price declines. On the other hand, when inflation rises, investors may seek value-preserving assets—Bitcoin is sometimes viewed as a hedge against inflation.
Data on interest rates, inflation, GDP growth, and unemployment can typically be obtained from national governments or international organizations like the World Bank or IMF. These datasets are usually available in CSV or JSON format and can be accessed through Python libraries like pandas_datareader.
The following table summarizes commonly used on-chain data, social media sentiment indicators, and macroeconomic factors, along with how they might influence cryptocurrency prices:

How to Integrate Feature Data
Generally, this process can be broken down into a few steps:
1. Data Cleaning and Standardization
Data from different sources may have different formats, some may be missing or inconsistent. In such cases, data cleaning is necessary. For example, converting all data to the same date format, filling missing data, and standardizing data so that it can be more easily compared.
2. Data Integration
After cleaning, data from different sources is merged based on dates, creating a complete dataset that shows market conditions for each day.
3. Constructing Model Input
Finally, this integrated data is transformed into a format the model can understand. For instance, if we want the model to predict today’s price based on data from the past 60 days, we would organize the data from those 60 days into a list (or matrix) to serve as the model’s input. The model learns the relationships within this data to predict future price trends.
The model can leverage more comprehensive information to improve prediction accuracy through this feature engineering process.
Open Source Project Examples
There are many popular open-source cryptocurrency price prediction projects on GitHub. These projects use various machine learning and deep learning models to predict the price trends of different cryptocurrencies.
Most projects utilize popular deep learning frameworks like TensorFlow or Keras to build and train models, learning patterns from historical price data, and predicting future price movements. The entire process typically includes data preprocessing (such as organizing and standardizing historical price data), model construction (defining LSTM layers and other necessary layers), model training (adjusting model parameters through a large dataset to reduce prediction errors), and final evaluation and visualization of prediction results.
One such project that uses deep learning techniques to predict cryptocurrency prices is Dat-TG/Cryptocurrency-Price-Prediction.
The main goal of this project is to use an LSTM model to predict the closing prices of Bitcoin (BTC-USD), Ethereum (ETH-USD), and Cardano (ADA-USD) to help investors better understand market trends. Users can clone the GitHub repository and run the application locally by following the provided instructions.

BTC Prediction Results for the Project (Source: Cryptocurrency Price Dashboard)
The code structure of this project is clear, with separate scripts and Jupyter Notebooks for obtaining data, training the model, and running the web application. Based on the project directory structure and internal code, the prediction model construction process is as follows:
- Data is downloaded from Yahoo Finance, and then cleaned and organized using Pandas, including tasks like standardizing the date format and filling in missing values.
- The processed data generates a “sliding window” — utilizing the past 60 days of data to predict the price for the 61st day.
- The data is then fed into a model built using LSTM (Long Short-Term Memory). LSTM effectively remembers short-term and long-term price changes, making it well-suited for predicting price trends.
- The prediction results and actual prices are displayed using various charts through Plotly Dash, with a dropdown menu allowing users to select different cryptocurrencies or technical indicators, updating the charts in real time.

Project Directory Structure (Source: Cryptocurrency-Price-Prediction)
Cryptocurrency Price Prediction Model Risk Analysis
Impact of Black Swan Events on Model Stability
A Black Swan event is extremely rare and unpredictable with a massive impact. These events are typically beyond the expectations of conventional predictive models and can cause significant market disruption. A typical example is the Luna crash in May 2022.
Luna, as an algorithmic stablecoin project, relied on a complex mechanism with its sister token LUNA for stability. In early May 2022, Luna’s stablecoin UST began decoupling from the US dollar, leading to panic selling by investors. Due to the algorithmic mechanism’s flaws, the collapse of UST caused the supply of LUNA to increase dramatically. Within a few days, the price of LUNA plummeted from nearly $80 to almost zero, evading hundreds of billions of dollars in market value. This caused significant losses for the involved investors and sparked widespread concerns about the systemic risks in the cryptocurrency market.
Thus, when a Black Swan event occurs, traditional machine learning models trained on historical data will likely never have encountered such extreme situations, leading the models to fail in making accurate predictions or even producing misleading results.
Intrinsic Risks of the Model
In addition to Black Swan events, we must also be aware of some inherent risks in the model itself, which may gradually accumulate and affect prediction accuracy in daily use.
(1) Data Skew and Outliers
In financial time series, data often exhibit skew or contain outliers. If proper data preprocessing is not performed, the model training process may be disrupted by noise, affecting prediction accuracy.
(2) Over-simplified Models and Insufficient Validation
Some studies may rely too heavily on a single mathematical structure when constructing models, such as using only the ARIMA model to capture linear trends while ignoring nonlinear factors in the market. This can lead to oversimplification of the model. Additionally, insufficient model validation can result in overly optimistic backtesting performance, but poor prediction results in actual applications (for example, overfitting leads to excellent performance on historical data but significant deviation in real-world usage).
(3) API Data Latency Risk
In live trading, if the model relies on APIs for real-time data, any delay in the API or failure to update data in time can directly impact the model’s operation and prediction results, leading to failure in live trading.
Measures to Enhance Prediction Model Stability
In the face of the risks mentioned above, corresponding measures need to be taken to improve the stability of the model. The following strategies are particularly important:
(1) Diverse Data Sources and Data Preprocessing
Combining multiple data sources (such as historical prices, trading volume, social sentiment data, etc.) can compensate for the shortcomings of a single model, while rigorous data cleaning, transformation, and splitting should be conducted. This approach enhances the model’s generalization ability and reduces the risks posed by data skew and outliers.
(2) Selecting Appropriate Model Evaluation Metrics
During the model construction process, it is essential to select the appropriate evaluation metrics based on the data characteristics (such as MAPE, RMSE, AIC, BIC, etc.) to assess the model’s performance and avoid overfitting comprehensively. Regular cross-validation and rolling forecasting are also critical steps to improve model robustness.
(3) Model Validation and Iteration
Once the model is established, it should undergo thorough validation using residual analysis and anomaly detection mechanisms. The prediction strategy should be adjusted continuously based on market changes. For example, introducing context-aware learning to adjust model parameters according to current market conditions dynamically is one approach. Additionally, combining traditional models with deep learning models to form a hybrid model is an effective method for improving prediction accuracy and stability.
Attention to Compliance Risks
Finally, in addition to technical risks, data privacy and compliance risks must be considered when using nontraditional data sources such as sentiment data. For example, the U.S. Securities and Exchange Commission (SEC) has strict review requirements regarding the collection and use of sentiment data to prevent legal risks arising from privacy issues.
This means that during the data collection process, personal identifiable information (such as usernames, personal details, etc.) must be anonymized. This aims to prevent personal privacy from being exposed while also avoiding improper use of the data. Additionally, it is essential to ensure that the collected data sources are legitimate and not obtained through improper means (such as unauthorized web scraping). It is also necessary to publicly disclose the data collection and usage methods, allowing investors and regulatory bodies to understand how the data is processed and applied. This transparency helps prevent data from being used to manipulate market sentiment.
Conclusion and Future Outlook
In conclusion, machine learning-based cryptocurrency price prediction models show great potential in addressing the market’s volatility and complexity. Integrating risk management strategies and continually exploring new model architectures and data integration methods will be important directions for the future development of cryptocurrency price prediction. With the advancement of machine learning technology, we believe that more accurate and stable cryptocurrency price prediction models will emerge, providing investors with stronger decision-making support.