Купути криптовалюту
Оплачуйте
USD
Купити та продати
HOT
Купуйте та продавайте криптовалюту через Apple Pay, картки, Google Pay, Банківський переказ тощо
P2P
0 Fees
Нульова комісія, понад 400 способів оплати та зручна купівля й продаж криптовалют
Gate Card
Криптовалютна платіжна картка, що дозволяє здійснювати безперешкодні глобальні транзакції.
Торгівля
Тип торгівлі
Спот
Вільно торгуйте криптовалютою
Alpha
Points
Отримуйте перспективні токени в спрощеній ончейн торгівлі
Премаркет
Торгуйте новими токенами до їх офіційного лістингу
Маржа
Збільшуйте свій прибуток за допомогою кредитного плеча
Конвертація та блокова торгівля
0 Fees
Торгуйте будь-яким обсягом без комісій та прослизань
Токени з кредитним плечем
Отримайте швидкий доступ до позицій кредитного плеча
Ф'ючерси
Ф'ючерси
Сотні контрактів розраховані в USDT або BTC
Опціони
HOT
Торгівля ванільними опціонами європейського зразка
Єдиний рахунок
Максимізуйте ефективність вашого капіталу
Демо торгівля
Запуск ф'ючерсів
Підготуйтеся до ф’ючерсної торгівлі
Ф'ючерсні події
Беріть участь у подіях, щоб виграти щедрі винагороди
Демо торгівля
Використовуйте віртуальні кошти для безризикової торгівлі
Earn
Запуск
CandyDrop
Збирайте цукерки, щоб заробити аірдропи
Launchpool
Швидкий стейкінг, заробляйте нові токени
HODLer Airdrop
Утримуйте GT і отримуйте масові аірдропи безкоштовно
Launchpad
Будьте першими в наступному великому проекту токенів
Alpha Поінти
NEW
Торгуйте ончейн-активами і насолоджуйтеся аірдроп-винагородами!
Ф'ючерсні бали
NEW
Заробляйте фʼючерсні бали та отримуйте аірдроп-винагороди
Інвестиції
Simple Earn
Заробляйте відсотки за допомогою неактивних токенів
Автоінвестування
Автоматичне інвестування на регулярній основі
Подвійні інвестиції
Купуйте дешево і продавайте дорого, щоб отримати прибуток від коливань цін
Soft Staking
Earn rewards with flexible staking
Криптопозика
0 Fees
Заставте одну криптовалюту, щоб позичити іншу
Центр кредитування
Єдиний центр кредитування
Центр багатства VIP
Індивідуальне управління капіталом сприяє зростанню ваших активів
Управління приватним капіталом
Індивідуальне управління активами для зростання ваших цифрових активів
Квантовий фонд
Найкраща команда з управління активами допоможе вам отримати прибуток без клопоту
Стейкінг
Стейкайте криптовалюту, щоб заробляти на продуктах PoS
BTC Стейкінг
HOT
Стейкайте BTC та отримуйте 10% APR
Випуск GUSD
Використовуйте USDT/USDC для випуску GUSD з дохідністю на рівні казначейських облігацій
Більше
imJoker
Контент поки що відсутній
imJoker
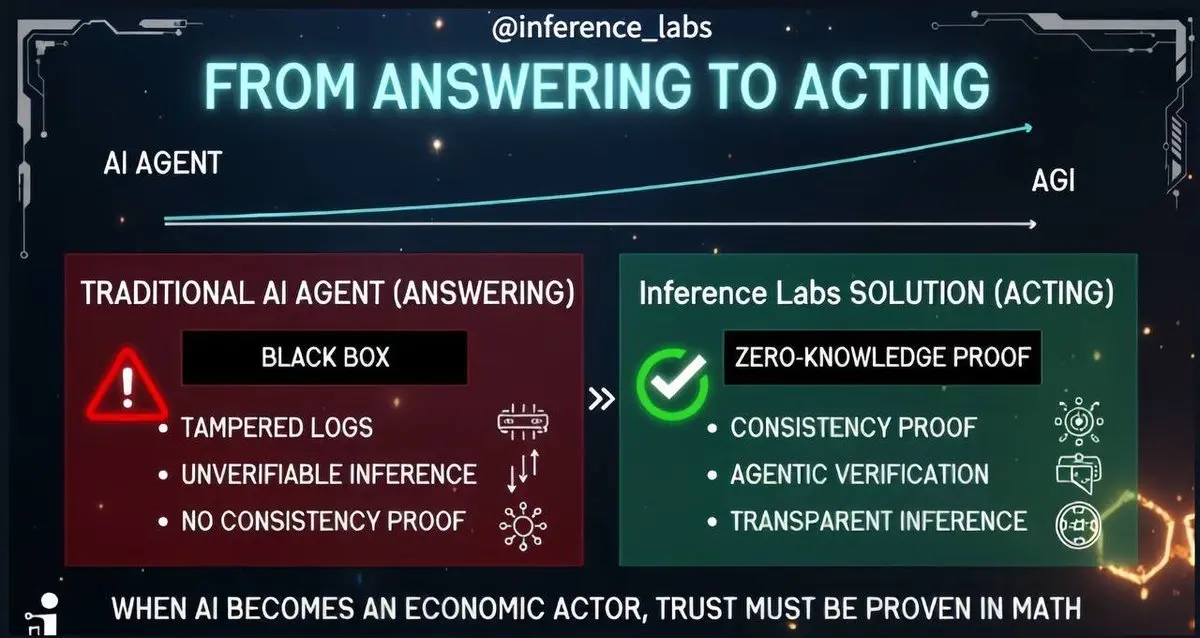
⚡️ Друзі, ШІ вже увійшов у нову еру, яка більше не обмежується лише генеруванням відповідей, а включає виконання платежів, операційних систем, проведення транзакцій і прийняття рішень.
Це означає, що ШІ більше не просто інструмент, а суб’єкт із здатністю діяти. Однак разом із цим виникає ключове питання: чи правильна та надійна поведінка цього агента (Agent)?
Існуюча архітектура ШІ не може дати відповіді на це питання. Журнали системи можуть бути підроблені, внутрішня логіка моделі — це чорний ящик, і її поведінку важко верифікувати з коренем.
У цьому контексті роль Inference Labs стає особлив
Це означає, що ШІ більше не просто інструмент, а суб’єкт із здатністю діяти. Однак разом із цим виникає ключове питання: чи правильна та надійна поведінка цього агента (Agent)?
Існуюча архітектура ШІ не може дати відповіді на це питання. Журнали системи можуть бути підроблені, внутрішня логіка моделі — це чорний ящик, і її поведінку важко верифікувати з коренем.
У цьому контексті роль Inference Labs стає особлив
KAITO-2.99%
- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
⚡️ Друзі, у децентралізованих фінансах (DeFi) трейдери та розробники постійно прагнуть до більш ефективних та розумних способів роботи.
Theoriq AI представила AlphaSwarm — революційну технологію, яка не є окремим торговим роботом, а групою інтелектуальних агентів, керованих штучним інтелектом, що діють як ефективний «фінансовий мозок» для самостійного прийняття рішень та співпраці.
Раніше стратегії торгівлі в DeFi часто вимагали складних смарт-контрактів або скриптів, але AlphaSwarm дозволяє користувачам вводити стратегії природною мовою, наприклад: «Купити, коли ціна ETH зросте на 3%». Група
Theoriq AI представила AlphaSwarm — революційну технологію, яка не є окремим торговим роботом, а групою інтелектуальних агентів, керованих штучним інтелектом, що діють як ефективний «фінансовий мозок» для самостійного прийняття рішень та співпраці.
Раніше стратегії торгівлі в DeFi часто вимагали складних смарт-контрактів або скриптів, але AlphaSwarm дозволяє користувачам вводити стратегії природною мовою, наприклад: «Купити, коли ціна ETH зросте на 3%». Група
ETH-1.79%

- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
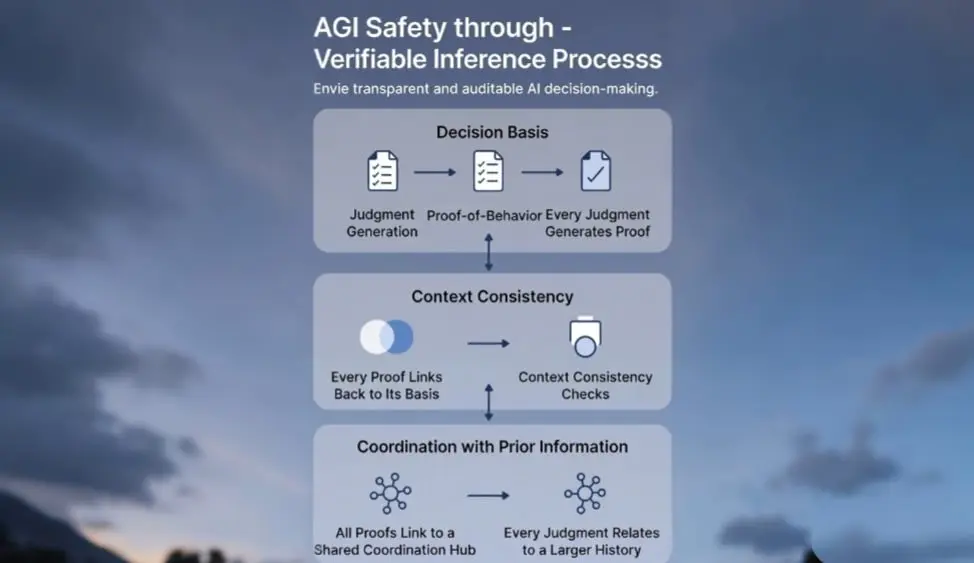
⚡️ Друзі, обговорення безпеки штучного інтелекту часто зазнають засмічення принциповими заявами, щоб уникнути упереджень, обмежити можливості, гарантувати надійність, але багато дискусій все ще залишаються на папері.
Наступні виклики вже перед нами — це перевірюваність самого процесу логіки. Помилки великих мовних моделей (LLM) є неминучими, проблемою ніколи не було випадкове помилкове рішення, а те, що ми не можемо чітко відстежувати логіку і підстави, на яких ґрунтується їхня оцінка.
Саме це є ядром безпеки AGI: потрібно не лише знати результат, а й розуміти “чому”. Лише тоді, коли процес ло
Переглянути оригіналНаступні виклики вже перед нами — це перевірюваність самого процесу логіки. Помилки великих мовних моделей (LLM) є неминучими, проблемою ніколи не було випадкове помилкове рішення, а те, що ми не можемо чітко відстежувати логіку і підстави, на яких ґрунтується їхня оцінка.
Саме це є ядром безпеки AGI: потрібно не лише знати результат, а й розуміти “чому”. Лише тоді, коли процес ло
- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
⚡️ Друзі, менше — це більше, коли Talus залишає складне собі, а просте віддає користувачам.
Коригування аірдропу в останню мить часто змушує спільноту підозрювати, чи не бракує команді ресурсу. Проте рішення Talus замінити $yUS Vault на $US демонструє протилежну мудрість: у ключові моменти мати сміливість спростити — це найбільша чесність щодо користувача.
Спрощення — це найефективніше наділення силою. $yUS як прибутковий актив має гарну ідею, але непомітно створює додатковий бар’єр у розумінні й ризики в управлінні для користувачів. Коли партнери не можуть гарантувати довгострокову стабільн
Переглянути оригіналКоригування аірдропу в останню мить часто змушує спільноту підозрювати, чи не бракує команді ресурсу. Проте рішення Talus замінити $yUS Vault на $US демонструє протилежну мудрість: у ключові моменти мати сміливість спростити — це найбільша чесність щодо користувача.
Спрощення — це найефективніше наділення силою. $yUS як прибутковий актив має гарну ідею, але непомітно створює додатковий бар’єр у розумінні й ризики в управлінні для користувачів. Коли партнери не можуть гарантувати довгострокову стабільн

- Нагородити
- 1
- Прокоментувати
- Репост
- Поділіться
⚡️ Друзі, від фінансової сфери до робототехніки, нове покоління інтелектуальних систем повинно не лише виконувати дії, а й мати здатність пояснювати та доводити кожне своє рішення.
Просто виконувати вже недостатньо — підзвітність стає новою основою. @inference_labs забезпечує це фундаментом: за допомогою перевірюваних обчислювальних процесів автономна поведінка перетворюється на аудиторську, надійну та перевірювану форму.
Кожна дія може бути математично доведена, логіка ухвалення рішень прозора та підлягає перевірці, автономні системи більше не є непрозорими або вразливими.
Високовартісні сист
Переглянути оригіналПросто виконувати вже недостатньо — підзвітність стає новою основою. @inference_labs забезпечує це фундаментом: за допомогою перевірюваних обчислювальних процесів автономна поведінка перетворюється на аудиторську, надійну та перевірювану форму.
Кожна дія може бути математично доведена, логіка ухвалення рішень прозора та підлягає перевірці, автономні системи більше не є непрозорими або вразливими.
Високовартісні сист

- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
⚡️ Друзі, досвід торгівлі часто вирішується у дрібницях. SDK v2.8.6 від Orderly Network — це ітерація, зосереджена на деталях, що робить дії користувача більш плавними та безпечними.
Один клік для реверсу позиції — це не просто нова кнопка, а спосіб врятувати вас від метушливого закриття та повторного відкриття позицій. Коли ринок змінюється, вам потрібна дія, а не процес.
Посилена логіка стоп-лосу — це чітке розмежування з непередбачуваністю. Вона захищає не від коливань ринку, а від додаткових витрат, викликаних недоліками механізму. Безпека не повинна бути справою випадку.
Чітка інформація
Один клік для реверсу позиції — це не просто нова кнопка, а спосіб врятувати вас від метушливого закриття та повторного відкриття позицій. Коли ринок змінюється, вам потрібна дія, а не процес.
Посилена логіка стоп-лосу — це чітке розмежування з непередбачуваністю. Вона захищає не від коливань ринку, а від додаткових витрат, викликаних недоліками механізму. Безпека не повинна бути справою випадку.
Чітка інформація
ORDER-2.23%

- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
⚡️ Друзі, витримка на спокійному ринку — це справжнє випробування. Обсяги торгів коливаються, але шлях ще довгий. Суботній ринок завжди більш млявий, особливо коли біткоїн втрачає позначку 90 000 доларів, і весь ринок занурюється в короткочасну тишу.
Дані Orderly Network також не стали винятком: обсяг торгів становив 65,16 млн доларів, що на 44,55% менше порівняно з попереднім періодом; дохід — 4 738 доларів, падіння майже наполовину. Цифри говорять самі за себе, і коливання — це норма для ринку.
Навіть у такій низці є 2 598 нових користувачів, які вирішили приєднатись. Це не випадковість, а с
Переглянути оригіналДані Orderly Network також не стали винятком: обсяг торгів становив 65,16 млн доларів, що на 44,55% менше порівняно з попереднім періодом; дохід — 4 738 доларів, падіння майже наполовину. Цифри говорять самі за себе, і коливання — це норма для ринку.
Навіть у такій низці є 2 598 нових користувачів, які вирішили приєднатись. Це не випадковість, а с

- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться
⚡️ Друзі, коли дані, обчислювальні потужності й моделі ШІ поступово концентруються в руках небагатьох гігантів, що звичайним людям лишається робити — пасивно чекати чи шукати інший шлях?
Проєкт під назвою Talus запропонував свою відповідь: зробити ШІ ресурсом на блокчейні, щоб кожен міг брати участь, надавати дозвіл і отримувати винагороду.
1. Чому саме зараз?
У сучасній гонці ШІ у звичайних людей майже немає права голосу. Дані зберігаються на серверах гігантів, обчислювальні потужності коштують шалені гроші, а моделі суворо контролюються. Talus прагне зламати цю монополію, винести ресурси ШІ
Переглянути оригіналПроєкт під назвою Talus запропонував свою відповідь: зробити ШІ ресурсом на блокчейні, щоб кожен міг брати участь, надавати дозвіл і отримувати винагороду.
1. Чому саме зараз?
У сучасній гонці ШІ у звичайних людей майже немає права голосу. Дані зберігаються на серверах гігантів, обчислювальні потужності коштують шалені гроші, а моделі суворо контролюються. Talus прагне зламати цю монополію, винести ресурси ШІ

- Нагородити
- подобається
- Прокоментувати
- Репост
- Поділіться