- Topic1/3
10k Popularity
12k Popularity
18k Popularity
5k Popularity
21k Popularity
- Pin
- #Gate 2025 Semi-Year Community Gala# voting is in progress! 🔥
Gate Square TOP 40 Creator Leaderboard is out
🙌 Vote to support your favorite creators: www.gate.com/activities/community-vote
Earn Votes by completing daily [Square] tasks. 30 delivered Votes = 1 lucky draw chance!
🎁 Win prizes like iPhone 16 Pro Max, Golden Bull Sculpture, Futures Voucher, and hot tokens.
The more you support, the higher your chances!
Vote to support creators now and win big!
https://www.gate.com/announcements/article/45974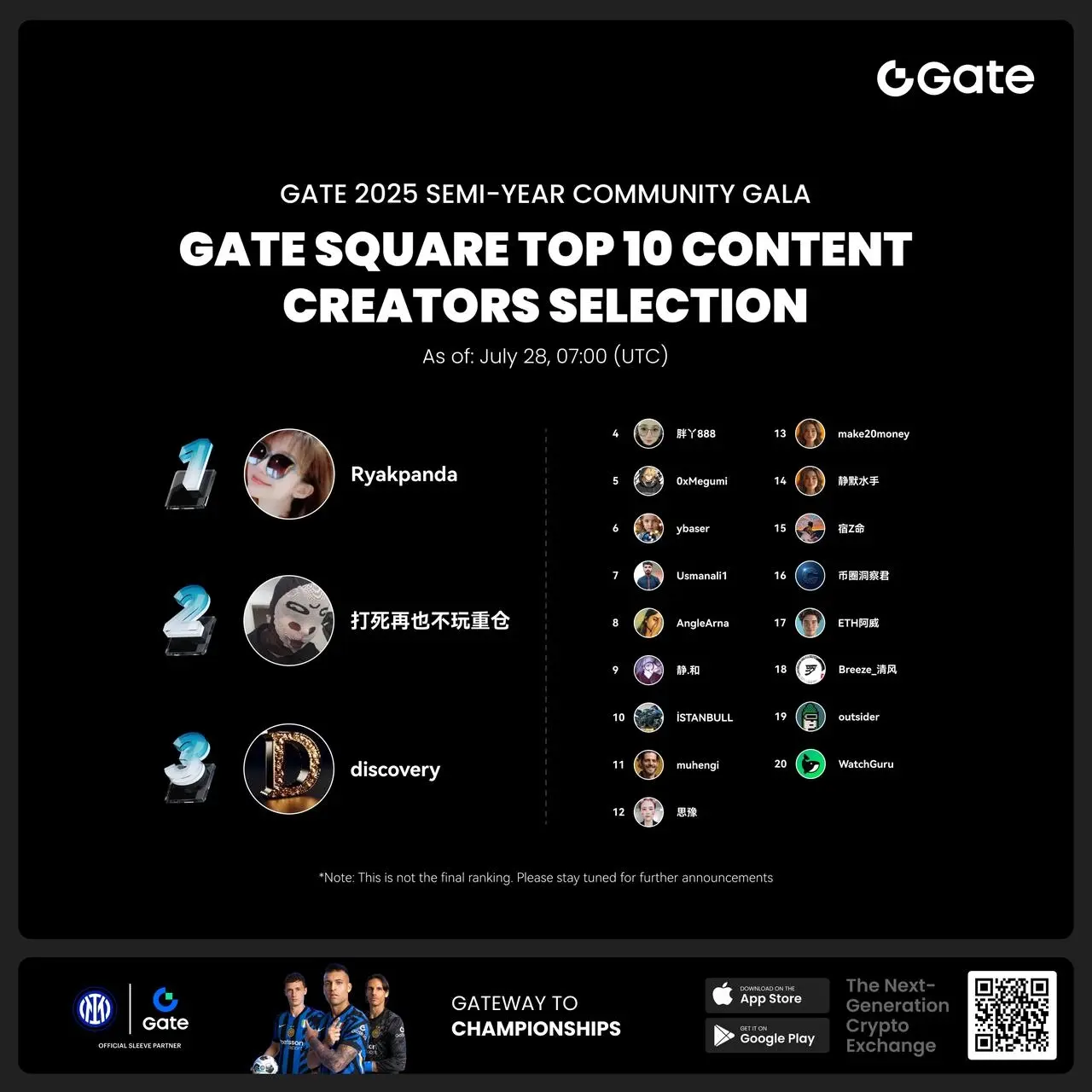
- 🎉 Hey Gate Square friends! Non-stop perks and endless excitement—our hottest posting reward events are ongoing now! The more you post, the more you win. Don’t miss your exclusive goodies! 🚀
1️⃣ #ETH Hits 4800# | Market Analysis & Prediction: Boldly share your ETH predictions to showcase your insights! 10 lucky users will split a 0.1 ETH prize!
Details 👉 https://www.gate.com/post/status/12322612
2️⃣ #Creator Campaign Phase 2# |ZKWASM Topic: Share original content about ZKWASM or its trading activity on X or Gate Square to win a share of 4,000 ZKWASM!
Details 👉 https://www.gate.com/post/st
Meta announced the audio2photoreal AI framework, which can generate character dialogue scenes by inputting dubbing files
Bit News Meta recently announced an AI framework called audio2photoreal, which is capable of generating a series of realistic NPC character models and automatically "lip-syncing" and "posing" the character models with the help of existing voice-over files.
The official research report pointed out that after receiving the dubbing file, the Audio2 photoreal framework will first generate a series of NPC models, and then use quantization technology and diffusion algorithm to generate model actions, in which quantization technology provides action sample reference for the framework and diffusion Algorithm is used to improve the effect of character actions generated by the frame.
Forty-three percent of the evaluators in the controlled experiment were "strongly satisfied" with the character dialogue scenes generated by the frame, so the researchers felt that the Audio2 photoreal framework was able to generate "more dynamic and expressive" movements than competing products in the industry. It is reported that the research team has now made the relevant code and dataset public on GitHub.