« Nous vivons une époque où le monde entier rivalise pour concevoir les meilleurs modèles fondamentaux d’intelligence artificielle. Si la puissance de calcul et l’architecture technique sont essentielles, la véritable barrière à l’entrée réside dans la qualité des données d’entraînement. »
— Sandeep Chinchali, Chief AI Officer, Story
Le potentiel du secteur des données IA : avis de Scale AI
L’un des événements marquants du secteur ce mois-ci est la démonstration de force de Meta, mobilisant d’importantes ressources financières, Mark Zuckerberg menant une intense campagne de recrutement pour bâtir un pôle d’excellence Meta AI, notamment avec de nombreux chercheurs chinois. À la tête de ce dynamisme, Alexander Wang, 28 ans, fondateur de Scale AI. Parti de rien, il a hissé Scale AI à une valorisation de 29 milliards de dollars, au service de clients aussi bien institutionnels (armée américaine) que concurrents directs (OpenAI, Anthropic ou même Meta). Ces géants dépendent de Scale AI pour l’accès à des données, activité principale de Scale : constituer et fournir d’immenses volumes de données annotées de qualité supérieure.
Pourquoi Scale AI s’est imposée comme la licorne emblématique du secteur ?
Sa force réside dans une prise de conscience précoce du rôle central joué par la donnée dans l’écosystème IA.
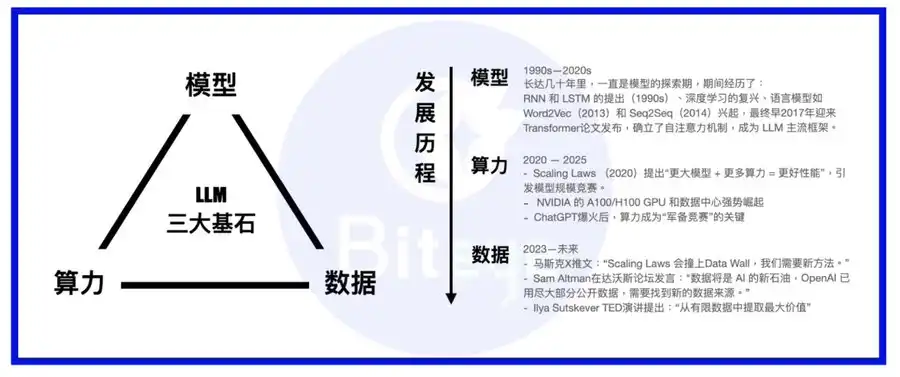
Pouvoir de calcul, modèles et données forment les trois piliers structurant l’IA. Imaginez le modèle comme le corps, la puissance de calcul comme la nourriture, et la donnée comme la connaissance et l’expérience.
Avec l’essor des grands modèles de langage, la priorité est passée de l’architecture des modèles à l’infrastructure de calcul. Désormais, la plupart des modèles phares utilisent l’architecture Transformer, ponctuée d’innovations telles que MoE ou MoRe. Les acteurs majeurs montent leurs propres superclusters ou concluent des contrats sur le long terme avec des fournisseurs cloud tels qu’AWS. Une fois la capacité de calcul sécurisée, l’attention se porte sur l’or noir : la donnée.
Alors que des sociétés comme Palantir ciblent la valorisation des données d’entreprise, Scale AI a fait le choix de bâtir une base de données solide dédiée à l’IA. Son activité dépasse le simple recyclage de bases existantes : elle s’inscrit dans la durée, avec la création d’équipes de formateurs humains experts, capables d’enrichir les modèles avec des données d’entraînement d’une qualité inégalée.
Encore sceptique ? Regardons comment un modèle IA est entraîné.
L’entraînement d’un modèle IA se déroule en deux temps : pré-entraînement puis ajustement fin (« fine-tuning »).
Le pré-entraînement s’apparente à l’apprentissage du langage chez un nourrisson : l’IA assimile de grandes masses de textes et de codes glanés sur le web pour acquérir les bases du langage naturel et de la communication.
L’ajustement fin, lui, est équivalent à l’enseignement scolaire, exigeant des réponses précises et vérifiables. Comme des établissements scolaires moulent les élèves selon leur programme, l’entraînement cible les modèles à partir de jeux de données soigneusement élaborés et adaptés à des compétences spécifiques.

Vous l’aurez compris, deux natures de données sont indispensables :
· D’une part, des volumes bruts nécessitant peu de traitement — ici, la quantité prime, issus de plateformes d’expression massive (Reddit, Twitter), de bibliothèques en accès libre ou de bases de données privées d’entreprises.
· D’autre part, des contenus élaborés et orientés — comme des manuels spécialisés, visant l’acquisition de compétences spécifiques. Ce corpus implique nettoyage, filtrage, annotation et validation humaine.
Ensemble, ces deux volets constituent l’épine dorsale de la donnée IA. D’un point de vue technologique, la simplicité peut parfois tromper : une fois les lois d’échelle du calcul atteintes, c’est la donnée qui devient la clé pour départager les fournisseurs de modèles de grande taille.
À mesure que les modèles progressent, la performance découle de plus en plus de données d’entraînement précises et spécialisées. Pour poursuivre la métaphore : former un modèle, c’est façonner un maître d’arts martiaux ; la donnée en est le manuel secret, la puissance de calcul en est l’élixir, et le modèle lui-même, le talent originel.
Sur le plan sectoriel, la donnée IA constitue un actif à rendement croissant : les premières générations de données produisent, grâce à leur accumulation, des effets composés sur la durée.
Web3 DataFi : le terreau idéal pour l’essor de la donnée IA
À rebours de la main-d’œuvre d’annotation externalisée à grande échelle de Scale AI (Philippines, Venezuela…), le Web3 offre des avantages propres dans la sphère « data IA », à travers l’émergence du DataFi.
Les atouts majeurs du DataFi Web3 sont multiples :
1. Propriété, sécurité et confidentialité des données via les smart contracts
Avec l’épuisement des sources publiques, l’exploitation de données inédites, privées, devient stratégique. D’où un choix de confiance : céder ses données à un acteur centralisé, ou conserver la propriété intellectuelle sur la blockchain, en traçant l’usage via smart contract ?
Pour la donnée sensible, technologies de preuve à divulgation nulle et environnements sécurisés (TEE) assurent qu’aucune information n’est exposée, la confidentialité étant pleine et entière.
2. Arbitrage géographique natif : mobiliser les talents du monde entier, de façon distribuée
Les modèles d’organisation classiques sont à repenser. Plutôt que d’aller dénicher la main-d’œuvre au moins disant salarial selon la logique de Scale AI, le Web3 s’appuie sur son architecture distribuée et des incitations transparentes pour impliquer équitablement une force de travail internationale.
Pour des tâches telles que l’annotation ou la validation de modèles, la diversité et la décentralisation réduisent les biais et élèvent la qualité globale des données.
3. Incitations et règlements transparents, facilités par la blockchain
Fini les systèmes opaques et peu fiables : les smart contracts introduisent des mécanismes d’incitation ouverts, automatiques, bien plus efficaces qu’une gestion manuelle équivoque.
La fin de la mondialisation complique l’arbitrage salarial transfrontalier. Avec les règlements sur blockchain, la participation et le versement de rémunération s’effectuent sans intermédiaire, n’importe où dans le monde.
4. Places de marché de données ouvertes, transparentes et directes
Les intermédiaires rognent systématiquement la valeur. Plutôt qu’une entreprise centralisée, les plateformes blockchain deviennent de véritables places de marché transparentes, à la Taobao, où acheteurs et vendeurs interagissent en direct, sans surcoût.
La demande pour la donnée IA sur blockchain va se segmenter et se sophistiquer, et seule une marketplace décentralisée peut y répondre à grande échelle.
DataFi : l’accès le plus simple à l’IA décentralisée pour les particuliers
La démocratisation du Web3 offre un accès inédit à la révolution IA, là où les outils centralisés restent réservés aux spécialistes, souvent onéreux ou complexes. Ici, nul besoin de contrats défavorables : un wallet suffit pour contribuer. On peut fournir ses données, annoter les résultats de modèles, évaluer l’IA, créer ou négocier des datas, la plupart du temps sans prérequis technique pour les habitués du Web3.
Projets DataFi Web3 à surveiller
L’investissement massif de Meta chez Scale AI (14,3 milliards de dollars) et l’explosion de la valorisation de Palantir traduisent l’émergence de DataFi dans le Web2. Dans le Web3, DataFi confirme son attrait auprès des investisseurs. À découvrir :
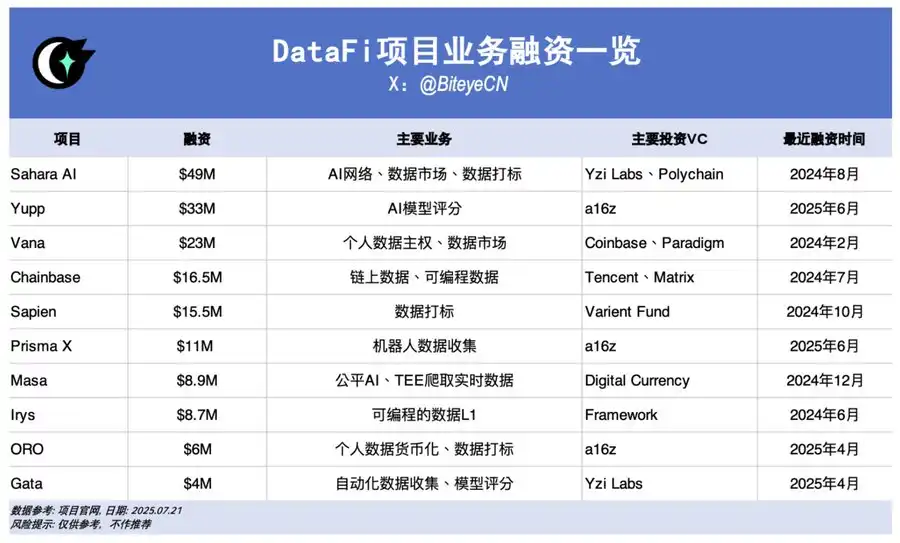
Sahara AI, @SaharaLabsAI, lève 49 millions de dollars
Vision : une super-infrastructure décentralisée et un marché global de la donnée IA. Sa DSP (Data Services Platform) en beta ouvre le 22 juillet, accordant des récompenses aux apporteurs de données et aux annotateu·r·rice·s.
Lien : app.saharaai.com
Yupp, @yupp_ai, lève 33 millions de dollars
Plateforme de feedback IA : les utilisateurs comparent différentes réponses à une même requête et sélectionnent la meilleure. Les points Yupp accumulés sont convertibles en USDC.
Lien : https://yupp.ai/
Vana, @vana, lève 23 millions de dollars
Vana transforme les données personnelles (navigation, réseaux sociaux) en actifs numériques. Elles sont mutualisées au sein de DataDAO et pools de liquidité pour l’entraînement IA, avec des jetons distribués aux contributeurs.
Lien : https://www.vana.org/collectives
Chainbase, @ChainbaseHQ, lève 16,5 millions de dollars
Chainbase structure les données issues de plus de 200 blockchains en actifs monétisables pour les développeurs DApp. Indexation, traitement par Manuscript et Theia AI. À ce stade, l’accès particulier reste limité.
Sapien, @JoinSapien, lève 15,5 millions de dollars
Sapien valorise à grande échelle le savoir humain sous forme de données d’entraînement IA. Ouvert à tous pour l’annotation ; la qualité est garantie par la relecture entre pairs. Notation longue durée et staking renforcent les gains.
Lien : https://earn.sapien.io/#hiw
Prisma X, @PrismaXai, lève 11 millions de dollars
Pierre angulaire de la coordination des robots, Prisma X mise sur la collecte physique de données. Participation possible via soutien à la collecte, pilotage à distance ou quiz pour engranger des points, à un stade encore précoce.
Lien : https://app.prismax.ai/whitepaper
Masa, @getmasafi, lève 8,9 millions de dollars
Masa se positionne comme leader du réseau Bittensor via ses sous-réseaux de données et d’agents. Données en temps réel, collecte depuis X/Twitter via TEE. Pour l’instant, le grand public y accède difficilement et à coût élevé.
Irys, @irys_xyz, lève 8,7 millions de dollars
Irys cible le stockage programmable, efficace et à bas coût de données pour l’IA et les DApps. Si peu d’options existent pour les utilisateurs, la phase testnet propose diverses activités de participation.
Lien : https://bitomokx.irys.xyz/
ORO, @getoro_xyz, lève 6 millions de dollars
ORO démocratise la contribution IA : connectez vos comptes (sociaux, santé, finance) ou réalisez des micro-tâches pour le testnet désormais ouvert.
Lien : app.getoro.xyz
Gata, @Gata_xyz, lève 4 millions de dollars
Gata, couche de données décentralisée, propose déjà trois offres : Data Agent (agents IA pour navigateur), All-in-One Chat (récompenses d’évaluation à la Yupp) et GPT-to-Earn (extension pour collecter les discussions ChatGPT).
Lien : https://app.gata.xyz/dataAgent
https://chromewebstore.google.com/detail/hhibbomloleicghkgmldapmghagagfao?utm_source=item-share-cb
Quels critères pour évaluer ces projets ?
À ce stade, l’accès technique reste ouvert, mais la fidélisation et la dynamique de communauté font très vite la différence. Investir tôt sur l’expérience utilisateur et des programmes d’incitation forts est clé : une plateforme ne perce que si elle acquiert une masse d’utilisateurs engagés.
Face à une activité très exigeante en main-d’œuvre, il faut aussi traiter la gestion des contributeurs et la qualité des données. Beaucoup de projets Web3 sont confrontés au phénomène des « farmers », attirés par le gain immédiat au détriment de la qualité. Si cette tendance perdure, les tricheurs finiront par évincer les bons contributeurs, détériorant la valeur des données et décourageant les acheteurs. Sahara, Sapien et d’autres placent la qualité au cœur de leur stratégie et cultivent des relations de long terme avec leurs apporteurs.
Autre enjeu, la transparence. L’équilibre délicat propre à la blockchain conduit souvent à des débuts plus centralisés, mais nombre de projets Web3 gardent un fonctionnement Web2 (données accessibles limitées, transparence floue). Cela nuit à la vitalité à long terme du DataFi. Espérons que les acteurs restent fidèles à leur ADN et accélèrent l’ouverture et la transparence.
Enfin, l’adoption massive du DataFi passera par deux leviers : enrôler suffisamment de particuliers pour alimenter la machine à données et créer une économie IA autonome, mais aussi convaincre les entreprises, aujourd’hui la principale source de revenus. Sahara AI, Vana et d’autres avancent déjà sur ces deux fronts.
Conclusion
Fondamentalement, le DataFi vise à valoriser l’intelligence humaine au profit de l’intelligence machine sur le long terme, en garantissant par smart contract la juste rémunération de la contribution humaine et en permettant à chacun de profiter de la croissance de l’IA.
Que l’on soit dans le doute face au nouvel âge de l’IA ou persuadé du potentiel de la blockchain malgré la volatilité crypto, s’impliquer dans le DataFi apparaît comme une option avisée et opportune.
Avertissement :
- Cet article est une republication de [BLOCKBEATS], tous droits réservés à l’auteur original [anci_hu49074, contributeur principal de Biteye]. Pour toute demande de republication, merci de contacter l’équipe Gate Learn pour un traitement rapide dans le respect des procédures.
- Mise en garde : Les opinions présentées n’engagent que l’auteur et ne constituent en aucun cas un conseil en investissement.
- D’autres versions linguistiques ont été produites par l’équipe Gate Learn. Sauf mention explicite de Gate, la reproduction, diffusion ou le plagiat des traductions sont interdits.







